Booster 插件⚓︎
作者: Hongxin Liu, Baizhou Zhang, Pengtai Xu
前置教程: - Booster API
引言⚓︎
正如 Booster API 中提到的,我们可以使用 booster 插件来自定义并行训练。在本教程中,我们将介绍如何使用 booster 插件。
我们现在提供以下插件:
- Torch DDP 插件: 它包装了
torch.nn.parallel.DistributedDataParallel并且可用于使用数据并行训练模型。 - Torch FSDP 插件: 它包装了
torch.distributed.fsdp.FullyShardedDataParallel并且可用于使用 Zero-dp 训练模型。 - Low Level Zero 插件: 它包装了
colossalai.zero.low_level.LowLevelZeroOptimizer,可用于使用 Zero-dp 训练模型。它仅支持 Zero 阶段1和阶段2。 - Gemini 插件: 它包装了 Gemini,Gemini 实现了基于Chunk内存管理和异构内存管理的 Zero-3。
- Hybrid Parallel 插件: 它为Shardformer,流水线管理器,混合精度运算,TorchDDP以及Zero-1/Zero-2功能提供了一个统一且简洁的接口。使用该插件可以简单高效地实现transformer模型在张量并行,流水线并行以及数据并行(DDP, Zero)间任意组合并行训练策略,同时支持多种训练速度和内存的优化工具。有关这些训练策略和优化工具的具体信息将在下一章中阐述。
更多插件即将推出。
插件选择⚓︎
- Torch DDP 插件: 适用于参数少于 20 亿的模型(例如 Bert-3m、GPT2-1.5b)。
- Torch FSDP 插件 / Low Level Zero 插件: 适用于参数少于 100 亿的模型(例如 GPTJ-6b、MegatronLM-8b)。
- Gemini 插件: 适合参数超过 100 亿的模型(例如 TuringNLG-17b),且跨节点带宽高、中小规模集群(千卡以下)的场景(例如 Llama2-70b)。
- Hybrid Parallel 插件: 适合参数超过 600 亿的模型、超长序列、超大词表等特殊模型,且跨节点带宽低、大规模集群(千卡以上)的场景(例如 GPT3-175b、Bloom-176b)。
插件⚓︎
Low Level Zero 插件⚓︎
该插件实现了 Zero-1 和 Zero-2(使用/不使用 CPU 卸载),使用reduce和gather来同步梯度和权重。
Zero-1 可以看作是 Torch DDP 更好的替代品,内存效率更高,速度更快。它可以很容易地用于混合并行。
Zero-2 不支持局部梯度累积。如果您坚持使用,虽然可以积累梯度,但不能降低通信成本。也就是说,同时使用流水线并行和 Zero-2 并不是一个好主意。
{{ autodoc:colossalai.booster.plugin.LowLevelZeroPlugin }}
我们已经测试了一些主流模型的兼容性,可能不支持以下模型:
timm.models.convit_base- dlrm and deepfm models in
torchrec
兼容性问题将在未来修复。
Gemini 插件⚓︎
这个插件实现了基于Chunk内存管理和异构内存管理的 Zero-3。它可以训练大型模型而不会损失太多速度。它也不支持局部梯度累积。更多详细信息,请参阅 Gemini 文档.
{{ autodoc:colossalai.booster.plugin.GeminiPlugin }}
Hybrid Parallel 插件⚓︎
这个插件实现了多种并行训练策略和优化工具的组合。Hybrid Parallel插件支持的功能大致可以被分为以下四个部分:
- Shardformer: Shardformer负责在张量并行以及流水线并行下切分模型的逻辑,以及前向/后向方法的重载,这个插件为Shardformer功能提供了一个简单易用的接口。与此同时,Shardformer还负责将包括fused normalization, flash attention (xformers), JIT和序列并行在内的各类优化工具融入重载后的前向/后向方法。更多关于Shardformer的信息请参考 Shardformer文档。下图展示了Shardformer与Hybrid Parallel插件所支持的功能。
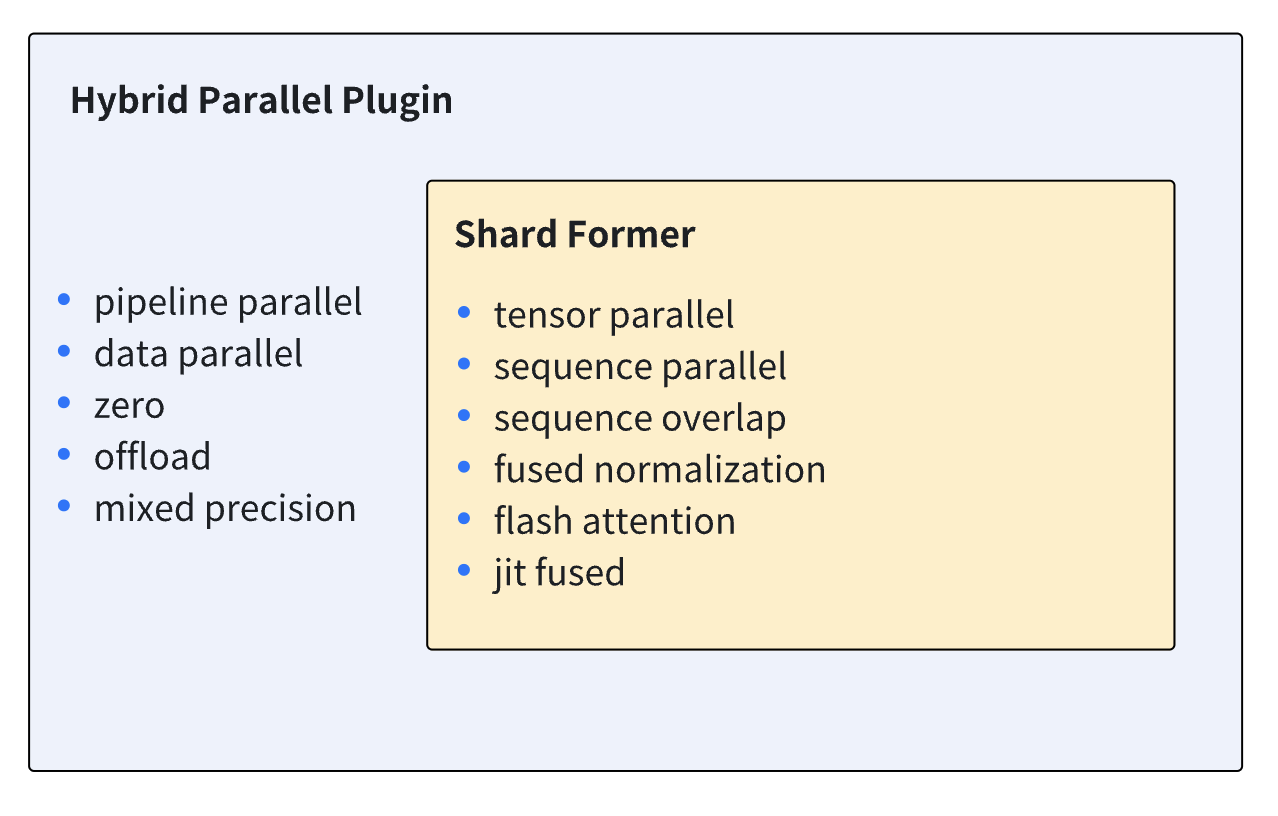
-
混合精度训练:插件支持fp16/bf16的混合精度训练。更多关于混合精度训练的参数配置的详细信息请参考 混合精度训练文档。
-
Torch DDP: 当流水线并行和Zero不被使用的时候,插件会自动采用Pytorch DDP作为数据并行的策略。更多关于Torch DDP的参数配置的详细信息请参考 Pytorch DDP 文档。
-
Zero: 在初始化插件的时候,可以通过将
zero_stage参数设置为1或2来让插件采用Zero 1/2作为数据并行的策略。Zero 1可以和流水线并行策略同时使用, 而Zero 2则不可以和流水线并行策略同时使用。更多关于Zero的参数配置的详细信息请参考 Low Level Zero 插件.
⚠ 在使用该插件的时候, 只有支持Shardformer的部分Huggingface transformers模型才能够使用张量并行、流水线并行以及优化工具。Llama 1、Llama 2、OPT、Bloom、Bert以及GPT2等主流transformers模型均已支持Shardformer。
{{ autodoc:colossalai.booster.plugin.HybridParallelPlugin }}
Torch DDP 插件⚓︎
更多详细信息,请参阅 Pytorch 文档.
{{ autodoc:colossalai.booster.plugin.TorchDDPPlugin }}
Torch FSDP 插件⚓︎
⚠ 如果 torch 版本低于 1.12.0,此插件将不可用。
⚠ 该插件现在还不支持保存/加载分片的模型 checkpoint。
⚠ 该插件现在还不支持使用了multi params group的optimizer。
更多详细信息,请参阅 Pytorch 文档.
{{ autodoc:colossalai.booster.plugin.TorchFSDPPlugin }}
创建日期: November 25, 2023