最佳性能的演示 (Maximum Performance)⚓︎
Tags: QUEUE, PERFORMANCE
假设您的 Gradio 演示在社交媒体上迅速走红-有很多用户同时尝试,您希望为用户提供最佳体验,换句话说就是尽量减少每个用户等待队列中查看他们的预测结果的时间。
如何配置您的 Gradio 演示以处理最大流量?在本指南中,我们将深入介绍 Gradio 的 .queue() 方法以及其他相关配置的一些参数,并讨论如何设置这些参数,以便您可以同时为大量用户提供服务,并使延迟保持最小。
这是一份高级指南,请确保您已经了解 Gradio 的基础知识,例如如何创建和启动 Gradio 界面。本指南中的大部分信息对于您是将演示托管在Hugging Face Spaces还是在自己的服务器上都是相关的。
启用 Gradio 的队列系统⚓︎
默认情况下,Gradio 演示不使用队列,而是通过 POST 请求将预测请求发送到托管 Gradio 服务器和 Python 代码的服务器。然而,常规 POST 请求有两个重要的限制:
(1) 它们会超时-大多数浏览器在 POST 请求在很短的时间(例如 1 分钟)内没有响应时会引发超时错误。 如果推理功能运行时间超过 1 分钟,或者当同时有很多人尝试您的演示时,增加了延迟。
(2) 它们不允许 Gradio 演示和 Gradio 服务器之间的双向通信。这意味着,例如,您无法实时获得您的预测完成所需的预计时间。
为了解决这些限制,任何 Gradio 应用都可以通过在 Interface 或 Blocks 启动之前添加 .queue() 来转换为使用 websockets。以下是一个示例:
app = gr.Interface(lambda x:x, "image", "image")
app.queue() # <-- Sets up a queue with default parameters
app.launch()
在上面的演示 app 中,预测现在将通过 websocket 发送。
与 POST 请求不同,websocket 不会超时并且允许双向通信。在 Gradio 服务器上,设置了一个 queue 队列,它将每个到达的请求添加到列表中。当一个工作线程可用时,第一个可用的请求将传递给工作线程用于预测。预测完成后,队列通过 websocket 将预测结果发送回调用该预测的特定 Gradio 用户。
注意:如果您将 Gradio 应用程序托管在Hugging Face Spaces,队列已经 enabled by default 默认启用。您仍然可以手动调用 .queue() 方法以配置下面描述的队列参数。
队列参数 (Queuing Parameters)⚓︎
有几个参数可用于配置队列,并帮助减少延迟。让我们逐个介绍。
concurrency_count 参数⚓︎
我们将首先探讨 queue() 的 concurrency_count 参数。该参数用于设置在 Gradio 服务器中将并行处理请求的工作线程数。默认情况下,此参数设置为 1,但增加此参数可以线性增加服务器处理请求的能力。
那为什么不将此参数设置得更高呢?请记住,由于请求是并行处理的,每个请求将消耗内存用于存储处理的数据和权重。这意味着,如果您将 concurrency_count 设置得过高,可能会导致内存溢出错误。如果 concurrency_count 过高,也可能出现不断切换不同工作线程的成本导致收益递减的情况。
推荐:将 concurrency_count 参数增加到能够获得性能提升或达到机器内存限制为止。您可以在此处了解有关 Hugging Face Spaces 机器规格的信息。
注:还有第二个参数可控制 Gradio 能够生成的总线程数,无论是否启用队列。这是 launch() 方法中的 max_threads 参数。当您增加 queue() 中的 concurrency_count 参数时,此参数也会自动增加。然而,在某些情况下,您可能希望手动增加此参数,例如,如果未启用队列。
max_size 参数⚓︎
减少等待时间的更直接的方法是防止过多的人加入队列。您可以使用 queue() 的 max_size 参数设置队列处理的最大请求数。如果请求在队列已经达到最大大小时到达,它将被拒绝加入队列,并且用户将收到一个错误提示,指示队列已满,请重试。默认情况下,max_size=None,表示没有限制可以加入队列的用户数量。
矛盾地,设置 max_size 通常可以改善用户体验,因为它可以防止用户因等待时间过长而被打消兴趣。对您的演示更感兴趣和投入的用户将继续尝试加入队列,并且能够更快地获得他们的结果。
推荐:为了获得更好的用户体验,请设置一个合理的 max_size,该值基于用户对预测所愿意等待多长时间的预期。
max_batch_size 参数⚓︎
增加 Gradio 演示的并行性的另一种方法是编写能够接受批次输入的函数。大多数深度学习模型可以比处理单个样本更高效地处理批次样本。
如果您编写的函数可以处理一批样本,Gradio 将自动将传入的请求批量处理并作为批量样本传递给您的函数。您需要将 batch 设置为 True(默认为 False),并根据函数能够处理的最大样本数设置 max_batch_size(默认为 4)。这两个参数可以传递给 gr.Interface() 或 Blocks 中的事件,例如 .click()。
虽然设置批次在概念上与使工作线程并行处理请求类似,但对于深度学习模型而言,它通常比设置 concurrency_count 更快。缺点是您可能需要稍微调整函数以接受批次样本而不是单个样本。
以下是一个不接受批次输入的函数的示例-它一次处理一个输入:
import time
def trim_words(word, length):
return w[:int(length)]
这是相同函数的重写版本,接受一批样本:
import time
def trim_words(words, lengths):
trimmed_words = []
for w, l in zip(words, lengths):
trimmed_words.append(w[:int(l)])
return [trimmed_words]
Setup 安装和设置⚓︎
建议:如果可能的话,请编写接受样本批次的函数,然后将 batch 设置为 True,并根据计算机的内存限制将 max_batch_size 设置得尽可能高。如果将 max_batch_size 设置为尽可能高,很可能需要将 concurrency_count 重新设置为 1,因为您将没有足够的内存来同时运行多个工作线程。
api_open 参数⚓︎
在创建 Gradio 演示时,您可能希望将所有流量限制为通过用户界面而不是通过自动为您的 Gradio 演示创建的编程 API进行。这一点很重要,因为当人们通过编程 API 进行请求时,可能会绕过正在等待队列中的用户并降低这些用户的体验。
建议:在演示中将 queue() 中的 api_open 参数设置为 False,以防止程序化请求。
升级硬件(GPU,TPU 等)⚓︎
如果您已经完成了以上所有步骤,但您的演示仍然不够快,您可以升级模型运行的硬件。将模型从 CPU 上运行切换到 GPU 上运行,深度学习模型的推理时间通常会提高 10 倍到 50 倍。
在 Hugging Face Spaces 上升级硬件非常简单。只需单击自己的 Space 中的 "Settings" 选项卡,然后选择所需的 Space 硬件。
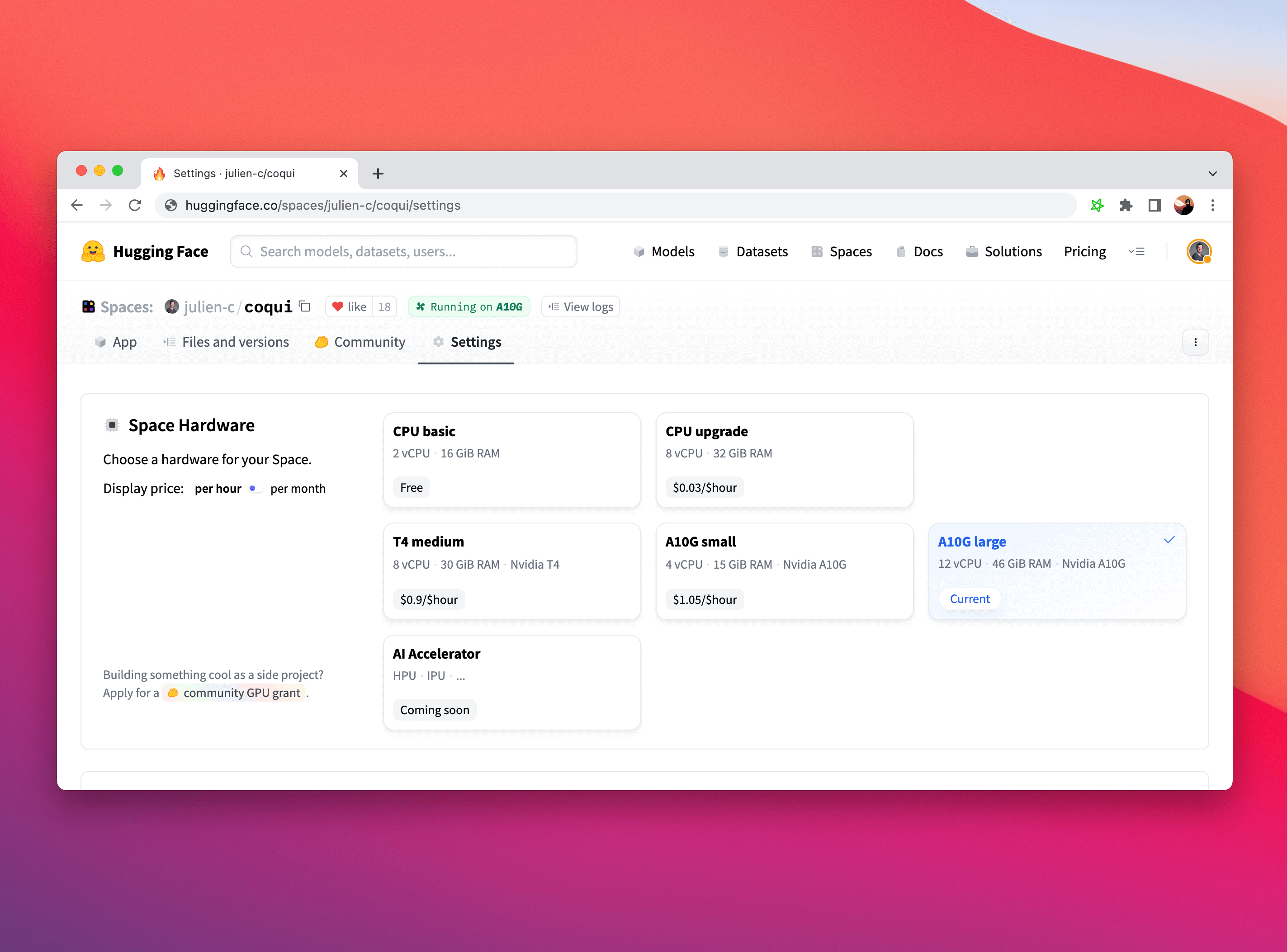
虽然您可能需要调整部分机器学习推理代码以在 GPU 上运行(如果您使用 PyTorch,这里有一个方便的指南),但 Gradio 对于硬件选择是完全无感知的,无论您是使用 CPU、GPU、TPU 还是其他任何硬件,都可以正常工作!
注意:您的 GPU 内存与 CPU 内存不同,因此如果您升级了硬件,您可能需要调整上面描述的concurrency_count 参数的值。
结论⚓︎
祝贺您!您已经了解如何设置 Gradio 演示以获得最佳性能。祝您在下一个病毒式演示中好运!
创建日期: November 25, 2023