模型设计相关说明⚓︎
YOLO 系列模型基类⚓︎
下图为 RangeKing@GitHub 提供,非常感谢!
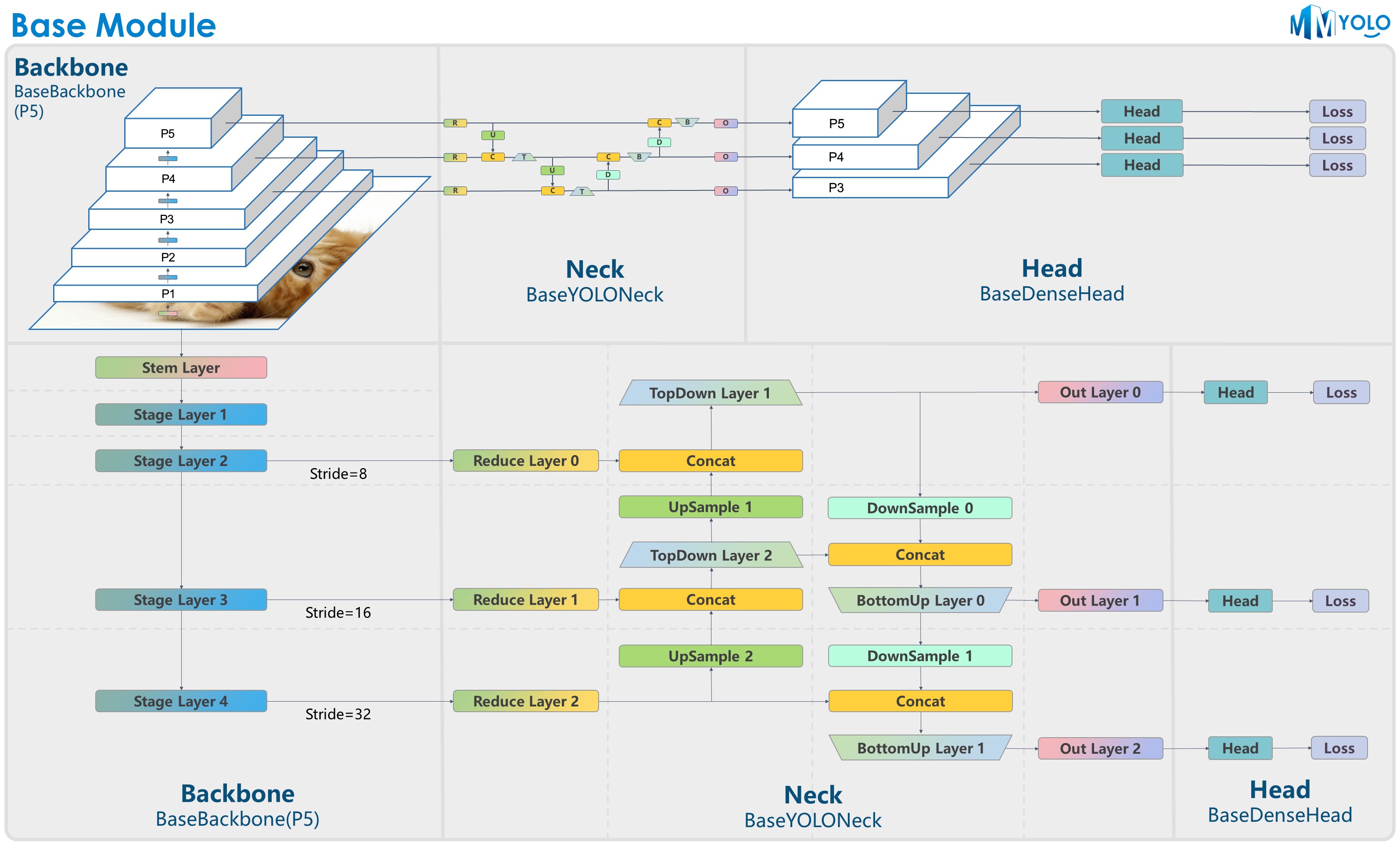
YOLO 系列算法大部分采用了统一的算法搭建结构,典型的如 Darknet + PAFPN。为了让用户快速理解 YOLO 系列算法架构,我们特意设计了如上图中的 BaseBackbone + BaseYOLONeck 结构。
抽象 BaseBackbone 的好处包括:
- 子类不需要关心 forward 过程,只要类似建造者模式一样构建模型即可。
- 可以通过配置实现定制插件功能,用户可以很方便的插入一些类似注意力模块。
- 所有子类自动支持 frozen 某些 stage 和 frozen bn 功能。
抽象 BaseYOLONeck 也有同样好处。
BaseBackbone⚓︎
如上图所示,对于 P5 而言,BaseBackbone 包括 1 个 stem 层 + 4 个 stage 层的类似 ResNet 的基础结构,不同算法的主干网络继承 BaseBackbone,用户可以通过实现内部的 build_xx 方法,使用自定义的基础模块来构建每一层的内部结构。
BaseYOLONeck⚓︎
与 BaseBackbone 的设计类似,我们为 MMYOLO 系列的 Neck 层进行了重构,主要分为 Reduce 层, UpSample 层,TopDown 层,DownSample 层,BottomUP 层以及输出卷积层,每一层结构都可以通过继承重写 build_xx 方法来实现自定义的内部结构。
BaseDenseHead⚓︎
MMYOLO 系列沿用 MMDetection 中设计的 BaseDenseHead 作为其 Head 结构的基类,但是进一步拆分了 HeadModule. 以 YOLOv5 为例,其 HeadModule 中的 forward 实现代替了原有的 forward 实现。
HeadModule⚓︎

如上图所示,虚线部分为 MMDetection 中的实现,实线部分为 MMYOLO 中的实现。MMYOLO版本与原实现相比具备具有以下优势:
- MMDetection 中将
bbox_head拆分为assigner+box coder+sampler三个大的组件,但由于 3 个组件之间的传递为了通用性,需要封装额外的对象来处理,统一之后用户可以不用进行拆分。不刻意强求划分三大组件的好处为:不再需要对内部数据进行数据封装,简化了代码逻辑,减轻了社区使用难度和算法复现难度。 - 速度更快,用户在自定义实现算法时候,可以不依赖于原有框架,对部分代码进行深度优化。
总的来说,在 MMYOLO 中只需要做到将 model + loss_by_feat 部分解耦,用户就可以通过修改配置实现任意模型配合任意的 loss_by_feat 计算过程。例如将 YOLOv5 模型应用 YOLOX 的 loss_by_feat 等。
以 MMDetection 中 YOLOX 配置为例,其 Head 模块配置写法为:
bbox_head=dict(
type='YOLOXHead',
num_classes=80,
in_channels=128,
feat_channels=128,
stacked_convs=2,
strides=(8, 16, 32),
use_depthwise=False,
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='Swish'),
...
loss_obj=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
reduction='sum',
loss_weight=1.0),
loss_l1=dict(type='L1Loss', reduction='sum', loss_weight=1.0)),
train_cfg=dict(assigner=dict(type='SimOTAAssigner', center_radius=2.5)),
在 MMYOLO 中抽取 head_module 后,新的配置写法为:
bbox_head=dict(
type='YOLOXHead',
head_module=dict(
type='YOLOXHeadModule',
num_classes=80,
in_channels=256,
feat_channels=256,
widen_factor=widen_factor,
stacked_convs=2,
featmap_strides=(8, 16, 32),
use_depthwise=False,
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='SiLU', inplace=True),
),
...
loss_obj=dict(
type='mmdet.CrossEntropyLoss',
use_sigmoid=True,
reduction='sum',
loss_weight=1.0),
loss_bbox_aux=dict(type='mmdet.L1Loss', reduction='sum', loss_weight=1.0)),
train_cfg=dict(
assigner=dict(
type='mmdet.SimOTAAssigner',
center_radius=2.5,
iou_calculator=dict(type='mmdet.BboxOverlaps2D'))),
创建日期: November 30, 2023