6.2.1 循环神经网络 RNN
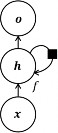
RNN 是一种专门用于处理序列数据的神经网络模型。与传统的前馈神经网络不同,RNN 具有记忆功能:模型能够在接收新数据的同时,同时保有对以往所有已经输入到模型中的数据的总结,即能够将先前的信息传递给后续的输入,以保留序列数据中的顺序关系,同时模型能够处理变长的序列输入。如图 6-2,RNN 的基本结构包括一个循环单元(Recurrent Unit)和一个隐藏状态(Hidden State):循环单元是 RNN 的基本构建块,它接收当前时间步的输入 x 和前一时间步的隐藏状态,并根据这两个输入计算当前时间步的输出 o 和隐藏状态。隐藏状态则可以看作是网络的内部记忆,它可以存储或总结之前所有时间步的信息,并在处理后续时间步时传递给下一层。
图 6-2 循环神经网络的基本结构,黑色的方块表示单个时间步的延迟
RNN 可以被看作是在时间维度上展开的多个相同的神经网络单元的集合,每个单元对应一个时间步,如图 6-3。当给定一个序列作为输入时,RNN 会按照时间步的顺序逐个处理每个输入,通过当前时间步的输入和前一时间步的隐藏状态计算当前时间步的输出和隐藏状态,并将隐藏状态传递给下一时间步。这种逐个处理的方式使得 RNN 在处理序列时能够“记住”上下文信息,从而对序列数据中的顺序信息进行正确的建模。
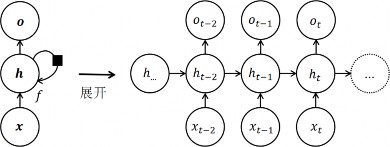
图 6-3 循环神经网络按照时间维度展开后的结构
6.2.1.1 LSTM
RNN 模型已被证实在面对序列输入时有着优异的表现。然而,传统的 RNN 也存在着短期记忆和梯度消失或爆炸等问题。即当序列数据较长时,网络无法有效地学习到长期的依赖关系。为了解决这个问题,长短期记忆(Long Short-Term Memory,LSTM)模型[27] 被提出。
LSTM 是一种特殊的 RNN 变体,其设计灵感源于计算机的逻辑门,即通过引入门控机制来控制序列数据中信息的流动和遗忘。 LSTM 具有三个关键的、带有可训练参数的门控单元:输入门、遗忘门和输出门,并通过它们决定网络中的信息流动。具体地,在 LSTM中,输入门负责决定哪些信息被更新;输出门决定哪些信息被输出;遗忘门决定哪些信息被忽略。三种门控单元都是(0,1)区间上取值的实数。与 RNN 相比,LSTM 额外引入了记忆单元(Memory Cell)以在不同的时间步存储和传递信息,即 LSTM 的隐藏状态可以看作由与RNN 类似的隐藏状态 H 和新引入的记忆单元 C 组成。
在每个时间步,模型先根据当前的输入数据和上一个时间步的隐藏状态来计算当前时间步下三个门控单元的值以及当前的记忆单元的候选值。然后,模型将当前的记忆单元的候选值送入输入门,将上一个时间步的记忆单元的值送入遗忘门,两者得到的结果求和作为当
前时间步最终的记忆单元的值。最后,模型将最终的记忆单元的值经过一个 Tanh 函数后送入输出门,得到的结果作为当前时间步的隐藏状态。
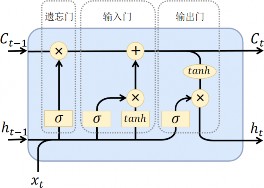
图 6-4 LSTM 结构图示
6.2.1.2 GRU
类似地,为了解决 RNN 中序列长期依赖问题,且同样采用了门控机制但相较于 LSTM 模型结构更简化的门控循环单元(GRU,Gated Recurrent Unit)模型被提出[28] 。与 LSTM 相比,GRU 只有重置门和更新门两个门且仅使用隐藏状态来存储和传递序列数据中的信息。其中重置门决定模型应该遗忘哪些过去的信息,更新门则决定了模型应该记住多少新信息,它们同样都是区间(0,1)上取值的实数。这样,在每个时间步更新隐藏状态时,GRU 便能通过控制这两个门的开关状态,自适应地选择保留需要的信息和遗忘不重要的信息,从而更好地处理长序列数据的依赖关系。具体地,在每个时间步,模型先根据当前的输入数据和上一个时间步的隐藏状态来计算当前时间步下重置门和更新门的值。然后,模型将上一个时间步的隐藏状态送入重置门,并结合当前的输入数据计算当前时间步的隐藏状态的候选值。最后,模型将上一个时间步的隐藏状态送入更新门,将当前时间步的隐藏状态的候选值与更新门中的值求反再加 1 后的值做按元素乘法,两
者得到的结果求和作为当前时间步的隐藏状态最终的值。
由于其处理序列数据时的出色表现,RNN 及其变体如 LSTM、 GRU 等模型被广泛应用到了自然语言处理(NLP,Natural Language Processing)领域中的各类任务。以英译中的机器翻译任务简单举例,模型每个时间步的输入为英文单词的特征表示,输出则为该英文单词对应的中文的特征表示。最后,由于“记忆”的存在,RNN 能够将输出的中文排列为通顺的语句。此外,循环神经网络也可用于股票价格预测、语音识别、文本生成等各类任务[41] ,并在许多实战场景取得了令人瞩目的成果。
但同时,RNN 也面对着诸多挑战与不足。例如梯度消失或爆炸问题:训练模型时,当输入的序列过长时,梯度可能会变得非常小或非常大,导致网络难以收敛或不稳定以及计算效率低下。这一问题还会更进一步导致 RNN 的短期记忆与难以处理长序列的问题,即模型趋向于“忘记”很早期的输入而仅能“记住”近期的输入,进而在处理较长的序列数据时遇到瓶颈。虽然 LSTM 和 GRU 等模型的提出一定程度上缓解了这个问题,但在序列更长、更复杂的场景中,这些问题仍然存在。另外,过于复杂的机制使得 LSTM 和 GRU 等很容易出现过拟合、调参困难、训练时间过长等问题,这些问题也有待进一步的解决。