2.4.4.1 LoRA 技术简介
随着预训练模型规模的增大,通过全微调 (full fine-tuning) 重新训练所有模型参数变得愈渐困难。例如,使用 Adam 微调的 GPT-3 175B 模型23部署独立实例的成本非常高昂,每个实例有 175B 个参数。为了解决这个问题,微软在 2021 年提出了一种名为低秩自适应
(LoRA)的方法24。
LoRA 的核心思想是冻结预训练模型的权重,并将可训练的秩分解矩阵注入 Transformer 架构的每一层中,这样可以显著减少下游任务需要训练的参数数量。与 GPT-3 175B 相比,LoRA 将可训练参数数量减少 10000 倍,并且减少了 GPU 内存需求。与 RoBERTa25、 DeBERTa26、GPT-227和GPT-3 等模型的微调结果相比,LoRA 在满足更少训练参数和更高吞吐量的同时,能取得与前者相当甚至更优的性能。此外,与适配器方法不同,LoRA 并没有引入额外的推理延迟。
IEEE/CVF conference on computer vision and pattern recognition, pages 10684-10695, 2022.
23 Brown T., et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
24 Hu J. E., et al. Lora: Low-rank adaptation of large language models[J]. arXiv preprint arXiv:2106.09685, 2021.
25 Liu Y., et al. Roberta: A robustly optimized bert pretraining approach[J]. arXiv preprint arXiv:1907.11692, 2019.
26 He P., et al. Deberta: Decoding-enhanced bert with disentangled attention[J]. arXiv preprint arXiv:2006.03654, 2020.
27 Radford A., et al. Language models are unsupervised multitask learners[J]. OpenAI blog, 2019, 1(8): 9.
![]()
LoRA 从Li 等人28和Aghajanyan 等人29的工作中获得灵感,后者表明,学习的过度参数化模型实际上存在于低内在维度上,所以论文提出了一种低秩自适应 (LoRA) 的方法。LoRA 允许通过优化适应过程中密集层变化的秩分解矩阵来间接训练神经网络中的一些密集层,同时保持预训练的权重不变。
![]()
![]()
![]()
假设给定一个由Φ参数化的预训练自回归语言模型 , LoRA 采用了一种有效的参数方法, 令任务特定参数增量由一组更小的参数 进一步编码。因此,求
的任务可转变为在Θ上进行优化:
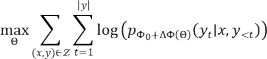
2.4.4.2 LoRA 在Stable Diffusion 上的应用
LoRA(Low-rank Adaptation)技术提供了一种快速微调扩散模型的方法,使得在不同概念(例如角色或特定风格)上训练 Stable Diffusion 模型更加便捷。经过训练的这些模型可以导出并供他人在其自身生成任务中使用。
Stable Diffusion 模型因其出色的图像和文本生成能力而在机器学习领域受到广泛关注。然而,这些模型的主要缺点之一是它们的文件大小较大,给个人计算机的维护带来困难。LoRA 技术通过引入低秩适应方法,为稳定扩散(Stable Diffusion)模型带来了诸多优势,
28 Li C., et al. Measuring the intrinsic dimension of objective landscapes[J]. arXiv preprint arXiv:1804.08838, 2018.
29 Aghajanyan A., et al. Intrinsic dimensionality explains the effectiveness of language model fine-tuning[J]. arXiv preprint arXiv:2012.13255, 2020.
特别是在应用于图像与文本生成任务方面。
使用LoRA 技术训练Stable Diffusion 具有几个关键优势:
1. 高效的微调过程
LoRA 允许使用低秩适应技术对扩散模型进行快速微调,相较于传统的优化方法,其在微调过程中大幅降低了计算成本和硬件要求。由于LoRA 不需要计算所有参数的梯度或维护优化器状态,仅需优化注入的远比原模型小的低秩矩阵,从而大幅简化了微调的计算复杂度。
2. 降低硬件门槛
由于稳定扩散模型本身在训练和推理过程中需要较大的计算资源和存储空间,这使得普通用户难以维护一个包含大量模型的收藏。 LoRA 技术的引入有效缩减了模型的文件大小,将其从原来的几 GB级别降低至 2-500 MB,使得用户能够更轻松地在个人计算机上运行和应用稳定扩散模型。
3. 保持模型质量
虽然LoRA 将稳定扩散模型文件大小大幅减小,但在此过程中并没有牺牲模型的生成质量。LoRA 技术在文件大小和训练能力之间取得了良好的平衡,使其成为拥有大量模型的用户的理想选择。用户可以获得高质量的图像与文本生成结果,而无需担忧过大的模型参数和计算成本。
4. 导出与分享
经过使用 LoRA 技术微调的稳定扩散模型仍然保持了较高的生成能力和多样性,这使得用户可以轻松导出和分享这些经过优化的模型供他人使用。导出的模型可以用于在不同概念(如角色或特定风格)上进行图像和文本的生成任务,为研究人员和开发者提供了更多实验和应用的可能性。
总的来说,LoRA 技术在稳定扩散模型中的应用为用户提供了更
高效的模型训练和应用体验。通过降低硬件门槛、保持模型质量和方便的模型导出,LoRA 为生成高质量图像和文本的研究和应用带来了更多的便利和可能性。