三维重建与新视角渲染作为计算机视觉中的一个核心议题,有着非常广泛的应用。然而基于传统多视角几何的方法对于稠密渲染任务性能欠佳,且计算量巨大。自 2020 年起,基于神经网络的神经渲染类方法取得了长足的进步,本文旨在简单回顾 NeRF 的原理以及潜在
systems, 2020, 33: 6840-6851.
34 Ho J., et al. Denoising diffusion probabilistic models[J]. Advances in neural information processing systems, 2020, 33: 6840-6851.
的应用。
2.4.6.1 NeRF 基本原理回顾
传统的 3D 重建与新视角渲染方法使用Mesh,Point Cloud,Voxel等方式来显式表示 3D 场景,然而由于显式表示的分辨率低,想获得照片级的渲染结果对于内存与计算的消耗都是指数级上升。隐式表示从另外一个角度解决了这个问题:隐式表示通常使用一个(可学习的)函数来描述场景,在 NeRF 出现之前,最为成功的案例是使用神经网络来近似Signed Distance Function 表示物体表面。
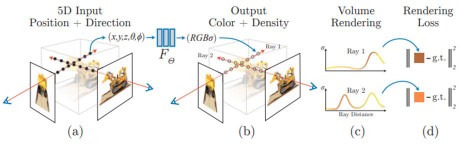
NeRF(Neural Radiance Field)首次将隐式表示带入了场景表示中来。简单来说,NeRF 训练的核心是得到以下函数:输入 3D 空间中的 (x, y, z) 坐标,以及对这个位置的观察角(θ, ɸ),输出该位置对应的颜色信息(r, g, b)以及对应的体密度.
图 2-8
基于这样的隐式场景表示,我们可以通过体渲染的方式得到任意观察视角的场景图像。简单地说,我们首先离散化该观察视角对应的射线得到一系列的位置,对于每个位置,通过该隐式神经网络预测对应的体密度与颜色值,后使用每个位置的体密度归一化值对对应颜色加权平均即可得到对应该像素的RGB 颜色值。
在训练阶段,我们输入同一场景的多张图像,以及对应的观察视角。对于每张图像的像素使用该隐式神经网络计算渲染结果,并计算损失函数,通过反向传播的方式优化该场景对应的隐式神经网络的参数,从而最终得到的隐式表示。对于新视角合成,我们则简单地使用此训练好的神经网络以及视角参数使用体渲染方法即可合成。
2.4.6.2 基于NeRF 的新兴应用
NeRF 方法本身后续有一系列的加速工作,使得 NeRF 的应用场景更加广泛,这里就不再展开,下文主要介绍一下基于 NeRF 原理的一系列新兴应用。
1.构建数字人体
IMAvatar 使用隐式神经网络从多帧人脸视频中分别学习几何、纹理、姿态和表情相关的形变场,并通过上述可微分渲染的方式进行端到端训练。在训练结束之后,可以无限制地操作虚拟形象外插至未见过少见的姿态和表情中。
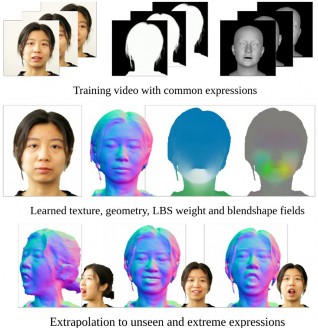
图 2-9
ICON 使用多帧无限制的分割完毕的人体全身图像作为输入,首先鲁棒地估计出每帧图片的法向图,并基于此使用隐式 3D 表示重建出人体形态。基于这样重建的结果,可以重新根据给定的姿态和需求渲染出虚拟形象,极大地拓展了数字世界中构建虚拟形象的成本与复杂度。

图 2-10