
基于海量图像数据训练的扩散模型使生成结果具有多样性,向用户展示出惊人的创造力,但其算法中引入随机噪声等环节也决定了生成结果的不稳定性是扩散模型在实际应用中无法回避的问题。AI 图像生成的不稳定性主要体现在生成内容的准确性和质量会随生成条
件等因素有所差别。因此,需要通过提示词、采样器等技术手段控制 AI 生成图像的内容、风格、尺寸等指标。这就如同在传统美术设计中,艺术家通过画笔形状、落笔轻重、颜料水分浓稠等准确地表达自己的创作意图和各种细节。
为了稳定控制 Stable Diffusion 模型的生成结果,主要有以下 3
种思路。
(1) 植入概念 (concept implantation)。当原有基础模型中不存在用户想表达的某事物时,可以通过模型微调技术,将概念与对应的形象植入到基础模型中。不论采用 Dreambooth39技术还是LoRA40技术,植入概念的方法是提供一批与新事物相关的图片,给这批图片赋予独特的标识,并将标识归到一个已存在的主题 (subject) 或类 (class)中。通过向基础模型植入概念,不仅可以控制生成所需的事物主体 (人物或物体) 和风格,还能控制细节内容、光影效果、姿态等。
(2) 注入条件 (condition injection)。当不便于用概念描述控制信息 (如动作、位置等) 时,可以对扩散模型的神经网络结构进行调整,将控制信息注入到生成过程中,即通过新增可控的神经网络结构 (例如线稿) 来约束扩散过程,从而实现准确的表达。目前常用的这类控制技术有ConttrolNet41和 Gligen42等,利用它们就能够以线稿/边缘图 (如 Canny 边缘、HED 边界、用户草图等)、深度图、人体姿势图 (OpenPose)、物体边界框等作为输入控制条件,引导图片生成。
39 Ruiz, Nataniel, et al. "Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023
40 https://huggingface.co/blog/zh/lora
41 Zhang, Lvmin, and Maneesh Agrawala. "Adding conditional control to text-to-image diffusion models." arXiv preprint arXiv:2302.05543 (2023).
42 Li, Yuheng, et al. "Gligen: Open-set grounded text-to-image generation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
(3) 改进模型 (model improvement)。如果要从根本上提升模型的性能,那么就需要考虑改进模型的设计。一个完整的扩散模型包括前向过程、反向过程、采样过程等很多组件,它们都会影响生成稳定性 43。最新发布的 Stable Diffusion XL (SDXL) 1.0 模型进行了全方位的优化44,比 Stable Diffusion 1.5 和 2.1 版本能提供更加优异的性能。例如,在 SDXL 模型训练阶段引入输入图像尺寸参数,使模型在训练过程中能够学习到图像的原始分辨率信息,从而在推理生成阶段更好地适应不同尺寸的图像生成,降低了模型对于输入图像分辨率的敏感性,提高了图像缩放条件下生成质量的稳定性。类似的,SDXL 训练还采取了图像裁剪参数条件化和多尺度训练策略,也有助于提高生成质量的稳定性。
稳定控制AI 图像的生成结果是一项复杂的任务,需要在模型设计、训练策略、数据处理和评估方法等方面进行综合考虑。在实际应用中,对于某些特定的任务,往往还需要通过人工干预,对生成结果进行筛选、标记和调整,通过评估与反馈的循环确保生成质量和可靠性。
解决方案 (solution) 是指针对特定问题或用户需求提供的完整的、可操作的解决方法,通常需要整合基于技术、软件、硬件等多方面的资源,是工程化成果的具体体现。在云计算背景下,解决方案是云计算服务商托管服务、合作伙伴产品,以及开源社区项目三者的有机组合,旨在满足客户或用户的具体需求,并解决特定的业务或技术
43 Podell, Dustin, et al. "SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis." arXiv preprint arXiv:2307.01952 (2023).
44 Chang, Ziyi, George A. Koulieris, and Hubert PH Shum. "On the Design Fundamentals of Diffusion Models: A Survey." arXiv preprint arXiv:2306.04542 (2023).
挑战。在生成式AI 应用领域,很多软件开发者、信息技术服务商、运营商等个人或企业,已经提供了多种多样的解决方案,将一系列最新的最佳实践和技术资产整合到一起,使用户能更高效、稳定、便捷地开展相关工作,减轻搭建生成式AI 工作环境的负担。
以亚马逊云科技为例,它面向客户与合作伙伴的实际业务需求,针对特定的业务场景,研发可重用的、经验证的、易于部署的解决方案,进一步帮助用户安全、高效、经济地利用云计算资源,在实际业务中便捷地获得AI 能力。亚马逊云科技解决方案的特点包括:(1) 代码开源,方案本身免费,客户只需要为解决方案运行时所消耗的云资源付费。(2) 支持CloudFormation 一键部署,使客户可快速完成部署,提升项目效率。(3) 解决方案的架构和代码经过亚马逊云科技的技术专家严格验证,体现优良架构 (Well-Architected) 的设计思想与最佳实践,有效降低成本,确保方案可靠。
2.5.5.1 亚马逊云科技典型的生成式AI 解决方案
Stable Diffusion WebUI 是目前最流行的 AI 图像生成的应用平台之一,但其单机运行的模式极大地影响了用户的工作效率。为了推动大规模的工程化应用,利用云计算的弹性算力资源成为克服单机运行瓶颈的最佳选择,但 Stable Diffusion WebUI 本身并没有提供接入云端算力资源的功能。
基于对用户需求的深入调研和分析,亚马逊云科技在 2023 年 6月推出了Stable Diffusion 插件解决方案,帮助用户将现有基于 Stable Diffusion WebUI 的模型训练、推理和调优等任务负载从本地服务器迁移至 Amazon SageMaker,利用云上弹性资源加速模型迭代,避免单机部署所带来的性能瓶颈。该方案为常用的 WebUI 原生功能/第三方插件提供云上工作流,包括txt2img、Img2img、LoRA、ControlNet、 Dreambooth (含LoRA 模型训练)、Image browser 等,能够满足设计人员和算法工程师的日常工作需求。
Stable Diffusion 插件解决方案主要具有以下特点:(1) 安装便捷,开箱即用:使用Amazon CloudFormation 一键部署亚马逊云科技的中间件,并以社区原生 Stable Diffusion WebUI 的插件形式一键安装前端插件,客户即可快速利用Amazon SageMaker 资源进行推理、训练和调优。(2) 社区原生,与时俱进:该方案以Stable Diffusion WebUI 的插件形式运行,用户不需要改变现有的 WebUI 使用习惯。方案插件和中间件的代码开源,采用非侵入式设计,有助于用户快速跟上社区相关功能的迭代,包括备受欢迎的Dreambooth、ControlNet 和LoRA等插件。(3) 扩展性强,迁移平顺:WebUI 界面与后端分离,WebUI可以在任何支持的终端上启动而没有GPU 的限制,原有的训练、推理等任务通过插件所提供的功能便捷地迁移到 Amazon SageMaker上,从而为用户提供弹性计算资源、降低成本、提高灵活性和可扩展性。
采用解决方案的优势,除了获得更加易用、安全的用户体验外,还在于能够得到亚马逊云科技在软件和硬件能力上的全面加持。以超分辨率重建为例,它是生成式AI 的一个重要应用方向,将低分辨率的图像、视频转换为高分辨率的版本,并且自动补充和恢复图像和视频在提升分辨率后的细节内容,改善用户的观看体验,在如广告设计、影视创作、游戏开发等领域有重要的应用价值。
亚马逊云科技的AI 视频超分辨率重建解决方案采用自研的基于深度学习的超分辨率算法,基于海量数据预先训练出AI 模型,普通用户开箱即用,不需要具备AI 技术能力。在工程实践上,该解决方案充分体现了亚马逊云科技多种服务在有机组合后带来的强大性能。一方面,它的架构使用 Amazon Batch 等服务分块批量作业,充分利用云上资源的弹性,缩短总处理时间,确保任务高效执行。当视频由 HD 转为 4K 分辨率时,在云资源充足的条件下,可通过并发加速达到 1:1 的处理速度 (即 1 分钟的原始视频只需1分钟即可处理完
毕),全面优于常规处理速度。另一方面,基于亚马逊云科技自研芯片Inferentia 实现高性能推理,与基于 CPU 或GPU 的传统方案相比,推理成本降低 55%;同时,它支持 Amazon EC2 Spot 实例,与按需实例的价格相比,使用Spot 实例最高可以享受多达 90%的折扣。
2.5.5.2 探索传统艺术创新的生成式AI 实践
亚马逊云科技的 Stable Diffusion WebUI 插件解决方案和丰富的托管服务为用户高效利用Stable Diffusion 开展生成式 AI 实践拓展了空间。借助这个解决方案,亚马逊云科技的大中华区解决方案研发中心与中央美术学院的实验艺术与科技艺术学院合作,利用生成式 AI为中国传统艺术注入新元素,在创新交互式艺术装置方面进行了有益的探索。
在亚马逊云科技 2023 中国峰会上,双方联合推出了“皮影随形” (GenAI Shadow Puppetry) 互动展位。这项工作展示了姿势分析、 txt2img、Dreambooth、LoRA 和ControlNet 等技术的新颖集成,主要包含 4 个步骤:(1) 创建交互式故事情节,(2) 训练皮影风格的LoRA模型,(3) 采用步骤 (2) 中训练的模型生成角色和相关素材,(4) 构建端到端的交互式体验。
在步骤 (1) 中,中央美术学院的师生们创作了叙事线索,编织出源于中国古代神话的故事情节,并融合进现代的故事形象,从而在过去与现在的反差碰撞中形成有趣的体验。在步骤 (2) 中,使用Amazon SageMaker 训练皮影风格模型。先利用 Grounding DINO 模型从经典皮影文献中提取不同的图像,如图 2-15 所示,并进行概念标注。再将精选的图像集作为LoRA 模型训练的概念注入,增强其创作能力。在步骤 (3) 中,生成超越传统皮影题材限制的新角色和素材,如宇航
员、火车和计算机等新颖的元素,如图 2-16 所示。在步骤 (4) 中,设计并实现互动体验,将设计的故事情节与参观流程结合起来。在观看某个皮影动画视频后,观众可以自由地做一些动作。利用 OpenPose
技术,从摄像头拍摄的观众动作视频中提取姿势数据,用于控制由 LoRA 模型生成的图像,生成互动动作的视频,如图 2-17 所示。最后,将互动动作视频与背景视频一起渲染,生成最终的作品,如图 2-18所示。为了确保生成视频中形象的一致性,并避免闪烁,在多个相邻帧之间进行姿势对齐, 将对齐的姿势帧组合成单个图像, 作为 ControlNet 的输入。
图 2-15 用于训练的原始皮影形象
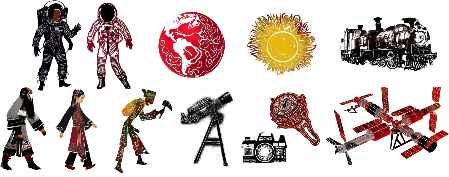
图 2-16 AI 生成的新皮影形象

图 2-17 通过动作控制生成的皮影形象

图 2-18 交互体验
图 2-19 所示为“皮影随形”互动展位的架构图,整个系统采用无服务器架构,利用了亚马逊云科技的多项服务。系统前端采用 React框架,将应用程序拆分成多个组件,每个组件都具有自己的状态和属性,便于单独控制和通信;同时,还使用了视频播放/采集相关技术,通过React Player 实现视频播放,使用 React Web Cam 采集视频数据。前端的网页及相关资源保存在Amazon S3 存储桶中,并通过 Amazon CloudFront 服务分发。对于系统后端,首先在客户端侧完成视频的抽帧与动作分析,并将结果通过API Gateway服务发送到云端的Amazon Lambda 服务处理。然后,Lambda 函数将每个请求保存到非关系型数据库Amazon DynamoDB 中,并触发Amazon SageMaker 进行推理。最后,Amazon SageMaker 根据用户的动作通过预训练模型生成皮影风格的图像集,生成结果被合成为视频后,保存在 Amazon S3 存储桶中。当观众扫描二维码请求访问视频时,Amazon Lambda 服务根据二维码中的 ID,从 Amazon S3 中获得生成视频的信息,由 Lambda函数生成临时访问链接,并返回给观众。
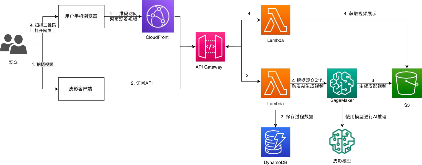
图 2-19 “皮影随形”互动展位架构图
不断发展的生成式AI 技术为该项目留下了更多的改进与创新空间。在创作过程上,根据前期中央美术学院师生的使用体验反馈,可以通过技术手段优化创作工具,进一步降低艺术工作者的工作量,帮助他们将精力集中在构思故事情节和微调细节上。例如:更加完整的单张图的生成技术,其中同时包括人物与背景;端到端直接生成视频,减少工作流中的人工操作;等等。在互动形式上,可以融入更多个性化元素,不止是观众的动作,还可以根据观众的面容、表情、服饰、性别等信息生成个性化内容。同时,还可以进一步提供手机端的体验。