
生成艺术是指使用计算机算法或人工智能技术创作的艺术作品。这些算法和技术能够模仿人类艺术家的风格和创作方式,从而产生独特的艺术作品。
生成艺术的核心是计算机程序通过学习艺术家的作品、图片、声音或文本等大量样本数据,来掌握并模仿创作者的创作风格。最常用的技术之一是“深度学习”,特别是基于神经网络的生成模型。这些模型在学习了大量数据后,能够生成具有相似特征的新作品。这一类作品主要包括图像、声音和文字生成类艺术作品。其中图像生成是探索最为广泛的领域,它专注于使用计算机算法和人工智能技术来生成艺术性的图像作品。在此类作品中,计算机程序通过学习大量的图像数据,例如绘画、摄影、图形等元素来创造出新的艺术图像。
在作品《Fifty Sisters(五十姐妹)》中,艺术家 Jon McCormack
将石油公司原始的图形元素作为基础数据集,利用人工智能技术不断学习植物形态,同时训练它具有一定独特的视觉语言,通过不断调优,从代码中生长出来的植物千姿百态。在这种创作方法背后,艺术家的身份也发生了一些转变。在传统绘画中,艺术家是作品的创作者,从构思到执行都是由艺术家亲自完成。他们运用自己的技巧、创意和感觉,通过手工绘制创作出艺术作品。然而在AI 生成绘画中,艺术家的角色更像是指导者或训练者。虽然他们仍然需要设计模型、选择算法和训练数据,但最终的图像是由计算机程序生成的,一部分创作过程被移交给了人工智能。在 Jon McCormack 的另一件作品《The Unknowable(不可知)》中展示了五种来自悉尼地区的本土植物,这些形态是通过模仿生物进化和发展的定制计算机程序生成而来。视频中这些植物在无尽的解体与重组中不断循环。AI 生成图形为艺术家提供了一个全新的探索领域。艺术家可以利用人工智能技术创作出以前难以想象的图像风格,实验不同的表现形式和创作方式,拓展艺术的边界。

图 2-21、图 2-22 Fifty Sisters(五十姐妹).Jon McCormack. 201245


图 2-23、图 2-24 The Unknowable(不可知).Jon McCormack.201746
45 https://jonmccormack.info/project/fifty-sisters
46 https://jonmccormack.info/project/the-unknowable
James Bridle47《The Cloud Index(云指数)》项目(2016)是一个与策展人、艺术家 Ben Vickers 合作的项目,Vickers 表示:“‘云指数’是一款软件,可以用来根据不同的政治结果创建不同的天气形态。”为了开发此项目,艺术家使用展示英国天气状况的卫星图像和显示英国与欧洲关系的英国脱欧投票结果来训练神经网络。云指数是通过分析 15000 多张天气模式的卫星图像,并将其与英国 2016 年欧盟公投前七年的民意调查数据相关联。这种分析是通过机器学习进行的,这是一种模拟大脑结构的神经网络,用以读取大量数据。虽然最初的提议有点荒诞,但 Bridle 巧妙地将人工智能、数据预测和天气结合在一起。他的作品涉及科技和社会问题的交汇,他通过艺术来引发观众对重要问题的思考,从而更深入地探索和呈现数字化时代的复杂性。


47 James Bridle 是一位擅长将艺术、技术和科学融合,以人工智能的方式揭露和分析当前的政治环境与
问题的艺术家。
图 2-25、图 2-26、图 2-27 The Cloud Index(云指数).James Bridle.201648
《Shiv Intege(r 整数刀)》是艺术家Matthew Plummer Fernandez 与
Julien Deswaef 合作完成的作品。它是一个能够创造集合艺术的 3D打印机器人。Thingiverse 是最大的在线 3D 打印社区,拥有庞大的用户制作模型库。Shiv Integer 作为定制软件会随机在 Thingiverse 上挑选模型,并将其组合成雕塑,并给它们起一堆由语无伦次的词构成的名字,比如“电子果汁高尔夫上的圆盘”。这个过程继承了达达主义的现成品艺术和偶发艺术传统,探讨了互联网文化中的知识共享、版权等问题,同时也在 Thingiverse 上引发了关于它是艺术还是垃圾的长期争论。
48 http://cloudindx.jamesbridle.com/


图 2-28、图 2-29、图 2-30 Shiv Integer(整数刀).Matthew Plummer Fernandez . 201649
49 .https://www.plummerfernandez.com/shiv-integer/
《Fall of the House of Usher II(厄舍古厦的倒塌Ⅱ)》是一个手工制作的数据集,包含两百多幅单独的水墨画,该作品基于 1929 年的无声电影《厄舍古厦的倒塌》而创作。反馈回路系统使用经过特殊修改的算法处理和复制图纸,然后使用生成对抗网络生成的镜头来构成下一个训练集的基础。重复、回忆和娱乐的概念是“古厦的倒塌”系列的核心。这部作品是继《厄舍古厦的倒塌》(2017)之后的系列作品中的第二部,该部分利用该数据集创建了 12 分钟的动画。

图 2-31 Fall of the House of Usher II(厄舍古厦的倒塌 II).Anna Ridler.201750
《人工智能无限电影》是艺术家与人工智能科学家合作开发的一个没有电影人(如导演、编剧、摄影师或演员等)参与的实时电影生成系统。观众可根据需求,输入电影类型(如科幻、犯罪、爱情等),再通过输入关键词或句子改变电影的叙事情节或风格,制作由AI 出品的永不重复的电影。此项目试图追求自然人创造不出来,又是自然人观影需要的传统电影里没有的成分。其理念的依据基于自然人的缺陷,例如:由于情感狭隘对问题判断的成见;政治、经济利益驱使导致的贪婪与邪念;知识量和视野所限。AI 站在冷静的立场,通过人
50 http://annaridler.com/fall-of-the-house-of-usher-ii
类各种影像素材的读取,提示人类整体生活观念的“内部结构”。这是对未来电影一种可能性的试验。

图 2-32 人工智能无限电影(AI-IF).徐冰. 2017 年至今51
AI 生成人脸一直备受关注,它引发人们对身份和隐私问题的思考的思考,作品《Portraits of Imaginary People(虚构人物肖像)》通过使用Flickr 上成千上万张人脸照片,输入到名为“生成对抗网络”
(GAN)的机器学习程序中,来探索人脸的潜在空间。GAN 的工作原理是利用两个神经网络进行对抗游戏:一个是“生成器”,旨在生成逐渐更具说服力的输出;另一个是“判别器”,旨在学习区分真实照片和人工生成的照片。最初,这两个网络在各自任务上都表现不佳。然而,随着“判别器”网络开始学会预测真假照片,它不断提醒“生成器”,迫使后者生成更难以区分、更具说服力的示例。为了跟上“生成器”的进展,生成器也不断改进,而“判别器”也必须相应地改进其识别能力。随着时间的推移,生成的图像变得越来越逼真,因为双方都竭力超越对方。因此观众看到的图像是神经网络从训练图像中学
51 https://www.xubing.com/cn/work/details/690?type=project#690
到的规则和内部关联的结果。作品以虚构人物肖像为中心,引发人们对真实性的关注。

图 2-33《Portraits of Imaginary People(虚构人物肖像)》Mike Tyka,201752
《Edmond de Belamy》是一幅由位于巴黎的艺术团体 Obvious 于 2018 年使用生成式对抗网络(GAN)构建的肖像画。该作品是以画布为媒介的,属于一系列名为《La Famille de Belamy》的生成图像。Belamy 这一名称是为了向生成式对抗网络的发明者 Ian Goodfellow 致敬53。在法语中,“bel ami”意为“好朋友”,因此它是 Goodfellow 这个名字的双关语翻译。该作品作为首幅使用人工智能创作的艺术品在佳士得拍卖行进行拍卖后,实际成交价高达 432500 美元,广受关注。
52 https://miketyka.com/?p=A%20fleeting%20memory
53 theverge.com. How three French students used borrowed code to put the first AI portrait in Christie’s[EB/OL].https://www.theverge.com/2018/10/23/18013190/ai-art-portrait-auction-christies-belamy-obvio us-robbie-barrat-gans.

图 2-34 《Edmond De Belamy》;材质:使用 GAN 算法生成,喷墨打印于画布;尺寸:70x70 厘米,2018
在 AI 艺术中,我们经常看到艺术家使用类似的代码,如 CycleGAN、SNGAN、 Pix2Pix 等,并使用从网络上抓取的相似数据集进行作品训练,这导致了图像的同质化问题,同时会让 AI 艺术显得重复和庸俗。为了应对这样的情况艺术家可以选择走在他人之前,永远都使用最先进的技术媒介进行创作,但新技术的使用并不能成为决定艺术作品“好”与“坏”的持久因素,艺术家应更专注于用自己的创作素材来训练 AI 模型,以确保作品的独特性,例如艺术家 Helena Sarin 使用自己训练的 GANs 来创作数字艺术,她可以在短时间内生成大量的作品草稿,并从中挑选出最具艺术价值的作品进行展示。

图 2-35 “四月赏花的游客大军 哦,他们是麻雀人”
bashoGAN 是用树木图像和俳句的书训练的模型
("troops of tourists come for april flower-viewing oh, they're sparrow-men"), Helena Sarin,201854
《Compressed Cinema(压缩电影)》是一个包含五个新的视听作品的系列,于 2020 年完成。这个系列的视频图像由Casey Reas 创作,每个作品都有由 Jan St. Werner 创作的立体声音轨。这些作品的理想展览空间是五个隔音的黑箱房间,地板设有舒适的座椅。视听作品将以墙面尺寸进行投影。声音通过高品质立体声扬声器系统回放。观众可以在房间自由走动,并可以花费任意时间于一个作品,每个循环体验都有所不同。这些视频可以在影院中从头到尾播放,也可以同时播放任意数量的视频,并以任意顺序播放,它们也可以作为电影/视频节目的一部分来观看,视频没有标题或片尾字幕,它们按照艺术家的意愿开始和结束。这些视频的图像是由 Casey Reas 使用生成对抗网络(GANs)创作的一组“电影截图”派生而来。这个过程在Reas
54 https://twitter.com/hashtag/bashoGAN?src=hash
的 2020 年著作《用生成对抗网络创造图片》(Making Pictures With Generative Adversarial Networks)中有详细记录。

图 2-36、图 2-37 COMPRESSED CINEMA(压缩电影).Casey Reas.2018–至今 (精选)55
Mario Klingemann 的《Memories of Passersby I(路人记忆 I)》是一个隐藏在古董家具中的计算机系统,家具看起来就像是中世纪的现代橱柜和老式收音机的混合体,作品利用神经网络实时地呈现不断变化的肖像,相比于由算法生成的单一图像,作品更关注于创造图像的计算机代码,艺术家通过改变、删除或交换训练数据的权重来操纵原有模型,这种引入的故障会导致模型误读输入数据,而呈现非常规视觉效果。作品向我们展示了机器如何在海量数据中“记忆”和“想象”人类面容。
55 https://reas.com/

图 2-38 Mario Klingemann 的《Memories of Passersby I(路人记忆 I)》201856
在Shinseungback 和Kimyonghun 的项目《Nonfacial Portrait,No.05
(非面部肖像之五)》中他们邀请艺术家为他人画面部肖像。画家们必须遵循一条规则:“肖像的脸不能被人工智能检测到。”在制作肖像时,三种人脸检测算法的相机会扫描画布,如果检测到任何人脸,显示器会通知艺术家。艺术家会参考它并修改这幅画。如果一个人的作品很“像”一幅肖像画,人工智能也将很容易检测到脸部。人们越是试图让它无法被人工智能识别,这幅画就越不会被视为人的肖像。人们必须找到只有人类才能感知的狭小视觉空间。在装置中,每幅肖像都与画家绘画过程的视频一起呈现。
56https://underdestruction.com/2018/12/29/memories-of-passersby-i/

图 2-39 Nonfacial Portrait,No.05(非面部肖像之五).Shinseungback Kimyonghun.201857
《合成抽象》是一系列抽象的屏幕打印图像,它们始终被主要图像识别系统(例如 Google、Amazon、Tumblr 等)注册为“成人”或 “露骨内容”。该系列探讨了机器如何感知露骨内容,是Tom White正在进行的关于机器如何观看、理解图像的研究。
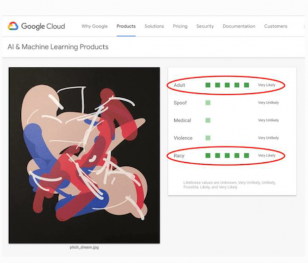
图 2-40 Synthetic Abstractions(合成抽象).Tom White.201858
58 https://aiartists.org/tom-white
White 称自己的版画是为了通过机器的眼睛看世界,并为机器“说话”发声。这种声音实际上是一系列算法,即“感知引擎”。“感知引擎”获取机器视觉算法训练的数据——包含数千张物体图片的数据库
——并将其提炼成抽象形状。然后将这些形状反馈到相同的算法中,以查看它们是否被识别。如果没有,图像会反复矫正,直到它被发送回去。这是基于图像生成技术设计的一个试验过程,本质上是算法理解世界的逆向工程。

图 2-41 Perception Engines(感知引擎).Tom White.201859
《nimiia cétiï( 火星萨满)》是艺术家 Jenna Sutela 与 Somerset House Studios 的常驻艺术家Memo Akten,以及谷歌艺术与文化实验室的创新负责人 Damien Henry 合作共同制作的一个新的视频装置。作品的灵感来自于物种间交流的实验,并渴望与我们意识之外的世界建立联系。这项工作记录了神经网络、早期火星语言的录音和太空细菌运动的镜头之间的相互作用,并使用机器学习生成了一种新的交流形式。
59 https://aiartists.org/tom-white
图 2-42 nimiia cétiï(火星萨满).Jenna Sutela. 201860
“Alt-C”是一种利用植物产生的电力为开采加密货币的单板计算机供电的装置。在光合作用过程中,绿色植物会释放土壤中的糖和有机物。这些营养物质随后会被释放电子的细菌消化。当电子在两个电极之间流动时,电流被用来为加密货币采矿设备供电。随着货币的生长,有可能得出大气条件与加密货币生产之间的相关性。Michael Sedbon 已经训练了一个人工智能神经网络来预测与英国天气预报相关的加密货币挖矿率。人工智能将试图制定一项战略,将种植、收获的资本再投资于可耕种的土地。

60 https://www.somersethouse.org.uk/whats-on/jenna-sutela-nimiia-cetii

图 2-43、图 2-44 《ALT-C》,Michael Sedbon. 201961
《Making Pictures With Generative Adversarial Networks( 用生成对抗网络创造图片)》是艺术家Casey Reas 首次介绍新兴人工智能技术的非技术性著作,艺术家在书中探讨了使用生成对抗网络(GANs),特别是深度卷积生成对抗网络(DCGANs)制作图片的感受。此书是为对人工智能技术的创造性应用感兴趣的读者编写的入门读物。希望读者可以探索这一新兴技术,并根据自己的理解对其进行改编。艺术家鼓励对机器智能时代的艺术进行严谨的讨论,希望激发更多的研究与合作。
61 https://michaelsedbon.com/Alt-C

图 2-45 Making Pictures With Generative Adversarial Networks(用生成对抗网络创造图片).Casey Reas.201962
作品《Western Flag(西部国旗)》描绘了 1901 年在德克萨斯州斯平德尔托普 (Spindletop )地区发现的世界上第一个重要石油开发地点“卢卡斯喷油井(Lucas Gusher)”,现在这个地点已经荒芜和枯竭,艺术家将其重新制作成数字模拟作品,作品中央有一根竖立的旗杆不断喷出黑烟。计算机生成的斯平德尔托普(Spindletop )在整个年份内与德克萨斯州的实际地点完全相同,太阳在适当的时间升起,白天根据季节变得长短不一。这个模拟程序由计算机程序实时计算每帧动画所需的内容。《西部国旗》位于科切拉谷和棕榈泉市的入口处,是对人类过度开发和耗尽资源的鲜明提醒。数百万年前,这片海床曾经生机勃勃,而现在却被迫变成了荒地,在这里升起人类“自我毁灭”的旗帜,提醒人们去思考在全球变暖和曾经肥沃土地变成沙
62 https://www.anteism.com/casey-reas-resources
漠的过程中人类所扮演的角色。作品中艺术家借用数字技术打破空间与时间的界限,在现实世界中创造出独特的视觉效果。作品不仅打破了传统艺术品的静态边界,而且为观众提供了更加身临其境的艺术体验。


图 2-46、图 2-47 Western Flag(西部国旗).John Gerrard. 201963
《一个有科技的女人》的第三部分是一个三屏视频(18 分 25 秒):基于行为过程中出现频率最高的关键词,在第一部分的记录文档中筛选出所有提到这个关键词的部分,然后拚贴剪辑而成。在这个过程中,
63http://www.johngerrard.net/western-flag-spindletop-texas-2017.html#2019-western-flag-spindletop-texas-20
17-at-desert-x-103
艺术家运用了人工智能(AI)技术中的 image detection(图像检测)和 dense caption(密集标题)功能,对所有视频中的图像进行了解读和抓取,即通过AI 去详细描绘视频中出现的所有内容。(此部分与艺术家汪洋合作完成)。
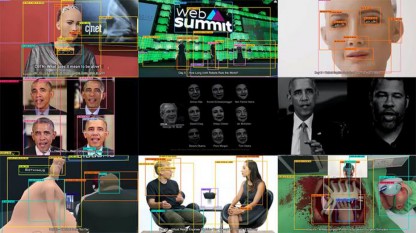
艺术家的实践不仅是探索新技术的可能,同时也会关注相关伦理问题,团队合作项目《Exposing AI》关注了那些因人脸数据收集而受到损害的人们,这些数据在全球范围内被用于增强警备和军事应用,但这些照片的使用并没有得到任何相关人员的知情或同意。在这个艺术项目Exposing.ai 中,用户可以在网站上寻找自己的人脸数据。这是一项关于隐私、监控、人脸识别的研究项目,该项目主要调查人们的照片如何在不知不觉中成为全球生物识别行业的信息数据,同时提出了问题:“我们如何在开放共享的行业大背景下保护用户的生物数据?”此外 Exposing.ai 项目的研究成果曾出现在《金融时报》、
《纽约时报》、《自然》杂志、美国政府问责局的报告、2020 年人工智能指数等多个媒体和学术研究论文中,并且在公共讨论中推动了关于数据集收集伦理问题的讨论。
64 http://www.unart.org.cn/cn/category/article-list/detail!wzy

图 2-49、图 2-50 Exposing.ai.Adam Harvey.201965
Deepfake 是用于合成人类面部、语音或视频的技术,已经成为生成艺术的一部分,其通过神经网络学习人的面部特征并在目标视频中重新生成或替换面部,从而创造出令人信服的假视频。
Deepfake 技术可以为艺术创作者提供新的创作手段和方式,但同时也带来了伦理和真实性的挑战。在艺术创作中使用 Deepfake 可以实现之前难以实现的创意,如替换电影角色的面部、重塑历史人物的影像等。但在其他领域,它可能被用于制造虚假新闻或误导公众,
65 https://exposing.ai/
因此需要谨慎使用。
AI 换脸作品《我们雨中看过你哭泣》是艺术家陈抱阳创作于 2019年 11 月,也是电影《银翼杀手》的背景设定时间。在电影中饰演 Roy的Hauer,面对试图终结他的人类赏金猎人 Rick 时,即兴创作了那段著名的“雨中之泪”独白。在这部作品中,Roy 的脸被老年化的Harrison Ford 所替代,他在电影中饰演了人类赏金猎人。Ford 面对着他自己年轻时的模样,谈论着人类的共情和他在那场神秘的战争中的经历。艺术家借 Deepfake 这种人工智能技术来叙述人与人工智能之间的联系,“就事论事”是一种创作的路径。


66 baoyangchen.com
作品《Zizi-Queering the Dataset(Zizi-重构数据集)》中艺术家 Jake Elwes 以 StyleGan (2019)为基础在包含 70,000 张人脸照片的 FFHQ(2018)数据集上进行了训练。正如艺术家在其网站上所言,面部识别算法和深度伪造技术目前很难辨别变性人、同性恋者和其他边缘化身份人士。虽然神经网络的灵感来源于人脑,但令人遗憾的是,它显示了我们在构建身份时存在的二元对立问题。作品旨在解决面部识别系统经常使用的训练数据缺乏代表性和多样性的问题。制作这段视频的方法是破坏这些系统的过程,艺术家用在网上找到的 1000 张变装和性别不固定的面孔图片对程序进行重新训练。这使得神经网络内部的权重从最初训练的规范性身份偏移,进入了一个涉及性别问题的领域。
作品《Zizi-Queering The Dataset》让我们得以窥探机器学习系统的内部,并直观地了解神经网络已经(和尚未)学到什么。这件作品是对差异和模糊性的赞美,让我们意识到数据驱动社会中的偏见。Zizi系列作品从 2019 年开始一直持续至今,是艺术家对人工智能与变装表演模糊地带的不断探索。变装表演挑战性别,探索异质性,而人工智能通常作为一个概念和工具被神秘化,并在复制社会偏见方面发挥着不可小觑的作用。Zizi 通过深度伪造,使用机器学习创建的合成变装身份,将这些主题结合在一起。

图 2-52 Zizi-Queering the Dataset(Zizi-重构数据集).Jake Elwes.201967

图 2-53 《Zizi-Queering the Dataset(Zizi-重构数据集)》Jake Elwes 2019 7 屏装置,Onassis Foundation, Pedion tou Areos Park, 雅典, 希腊68
Sofia Crespo 是一位对生物学相关技术有着浓厚兴趣的艺术家。她的主要关注点之一是有机生命使用人工机制来模拟自身生成和进化的方式,这意味着技术并不是与有机生命完全分离的,而是基于对已有有机生命的认识而产生的。Crespo 着眼于人工智能图像生成技术与人类创造性地表达自己和认识世界的方式之间的相似之处。她的作品质疑人工智能在艺术实践中的潜力及其重塑我们对创造力的理解
67 https://www.jakeelwes.com/project-zizi-2019.html
68 https://www.jakeelwes.com/project-zizi-2019.html
的能力。另一方面,她还非常关注使用机器学习技术的艺术家角色的变化。在这件作品中,Crespo 提炼了我们通常对于水母“本质”或特征的看法和理解。她认为,我们对于不同事物本质的认识在相互碰撞和冲突的过程中可以产生一种潜在的梦幻般的效果,我们会在看到的既有事物中寻找共鸣。“使用深度学习算法,我们可以在数字领域探索我们与自然世界的互动,模糊人工生命和自然之间的界限。”69
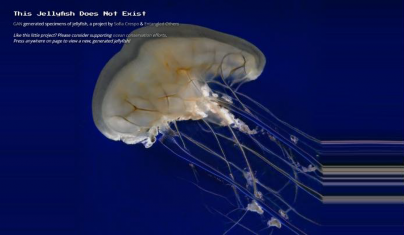
图 2-54 This Jelllyfish Does Not Exist(这个水母并不存在).Sofia Creapo.2020-202170
Martine Syms 从事视频、文本、表演和动态图像方面的创作,她的视频装置作品《eural Swamp(神经沼泽)》挑战了种族和性别的陈规陋习,并探讨了在一个超数字化的世界中作为黑人和女性的意义。作品是五个屏幕组成的的装置空间,艺术家将已编写好的脚本用来生成图像、视频和文字,作品中的五个声音中,有两个是机器学习提供的,艺术家利用算法和人工智能来质疑图像的政治性,同时在思考技术是如何改变我们彼此的沟通方式。

图 2-55 Neural Swamp (神经沼泽).Martine Symsi.202171
《THE CROW(乌鸦)》2022 戛纳电影短片节最佳短片。艺术家 Glenn Marshal 用 OpenAI 的 CLIP 创建的短片(CLIP 是一个神经网络,可以通过自然语言监督高效地学习视觉概念)艺术家将真人舞蹈《Painted》的视频输入 CLIP,然后让系统生成一段“乌鸦在荒凉景观中的绘画”视频,艺术家表示,“生成的结果几乎不需要刻意挑选。他将这归功于提示词和底层视频之间的相似性,底层视频中描绘了一个披着黑色披肩的舞者模仿乌鸦的动作在舞蹈,AI 让每一帧画面看起来都像是真实的。”

71 https://metrophiladelphia.com/martine-syms-neural-swamp/

,
图 2-56、图 2-57 《乌鸦》(THE CROW),Glenn Marshal,202272
《AB INFINITE 1(AB 无限 1)》是艺术家 Andrea Bonaceto 的代表作,展现了艺术家和观众之间的开创性合作。Bonaceto 将这部作品描述为“迄今为止我最深刻的作品”。该作品提供了他生活和文化循环的快照,为旅程“ab Infinite”(拉丁语中的“来自无限”,是他名字首字母的双关语)赋予了意义。该作品的观众可以使用 Instagram 和 Twitter 上的#abinfinite1 标签上传图像,图像将通过 Bonaceto 人工智能算法进行翻译,然后纳入作品独特的视觉词汇中。通过同样的过程,在主题标签下发布的任何文本都成为作品中展示的一首不断演变诗歌,让人想起詹姆斯·乔伊斯的《尤利西斯》的足迹中建立的现代意识流。《AB INFINITE 1》是使用Algorand 区块链上的ARC-19 标准创建的可变 NFT 。这使得 NFT 能够更新其 IPFS URL(图像),从而允许创建随时间变化的 NFT。
![]()
图 2-58 AB Infinite 1 (AB 无限 1).Andrea Bonaceto.202273
作品《Unsupervised(无监督)》是艺术家 Refik Anadol 长期项目
《Machine Hallucinations(机器幻觉)》的一部分,探索基于集体视
72 https://www.youtube.com/watch?v=pK7AGfBtw1Q
73 https://www.abinfinite1.com/about
觉记忆的数据美学空间。自 2016 年项目启动以来,Anadol 将智能机器作为人类的合作者,利用 DCGAN、PGAN 和 StyleGAN 算法,以庞大的数据作为基础进行训练,以展开探索。Anadol 和他的团队从数字档案和公共资源中收集数据,并使用机器学习分类模型处理这些数据集。作为一种精心策划的多渠道体验,《Machine Hallucinations
(机器幻觉》为观众带来了一种自我再生的惊喜感,并通过控制论的偶然性提供了一种新的感官自主形式。Refik Anadol 也曾在演讲中提出“将数据作为颜料”的创新思路。这会是人们以 AI 技术记录历史,进行艺术创作的新方法。
《Unsupervised NFT Collection》正是从这样的美学愿景中产生,它将来自现代艺术博物馆(MoMA)庞大藏品的 138,151 条原数据处理在机器的“头脑”中。使用StyleGAN2 ADA 捕捉机器对现代艺术在多维空间中的“幻觉”,Anadol 用MoMA 艺术品收藏的子集训练了一种独特的AI 模型,创建了 1024 维度的嵌入,并对排序后的图像数据集进行分类,以更好地理解数据的语义和上下文。这个不断扩展的数据宇宙不仅代表了数据的插值合成,还成为一种潜在的宇宙,在其中由一种新形式的艺术创造力产生的幻觉潜力解释着 MoMA 无与伦比的现代与当代艺术收藏。

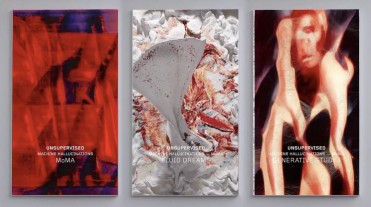
图 2-59、图 2-60 Unsupervised(无监督).Refik Anadol.202274
在艺术家兼制作人 Riar Rizaldi 创作的电影《化石》(Fossilis)中,他用自己的作品审视资本、技术、世界和小说的相互作用,在电影中,AI 生成的图像是物理世界和虚拟世界之间的边缘过渡,考古学家使用的机器会思考如何构建一个可以虚拟观察这些电子垃圾的世界。要形成这个虚拟世界,它需要古人类留下的电子垃圾数据集图像。艺术家在制作影片时将数字和物理废物融入到艺术实践里,《化石》的拍摄场景是由废弃的垃圾制成的,例如未使用的电缆、废弃的金属板和化粪池。《化石》中的 CGI(Computer-generated imagery)是废弃的 CGI 资产的复制品。AI 生成的图像取自 ImageNet(是一
74 https://refikanadol.com/works/unsupervised/(关于该项目的更多信息请参阅MoMA Magazine: https://www.moma.org/magazine/articles/658
个用于视觉对象识别软件研究的大型可视化数据库)数据集中的电子垃圾图像。最后,街景取自印度尼西亚的“电子尸体”市场:这是一个人们出售电子废弃物的市场.这些动态影像制作技术在处理废弃物和闲置物的概念上各有千秋,既有物理上的,也有数字上的。此外,使用不同的技术也会带来不同的感官体验,这也是艺术家在这个作品中想看到的效果。

图 2-61 《Fossilis(化石)》幕后图像.Riar Rizaldi.202375
当代艺术家蔡国强的人工智能艺术计划 cAI™ (读作 AI CAI),是从其数十年的艺术哲学与方法论出发而量身开发人工智能程序。它能够深度学习蔡国强的艺术创作、著述、影像与档案资料,以及宇宙和未知世界等领域的知识。cAI™作为随着前沿科技与艺术家人生进程不断有机生长的多模态综合体,它本身既属于蔡国强的AI 艺术作品,也是其创作中的合作伙伴,未来亦可能独立创作。这无疑是一个实验性的艺术计划。关于 cAI™蔡国强谈到:“火药和 AI 对我来说都是难以捉摸和控制的媒介,但正因此令人着迷。火药自有神奇的‘生命力’,但需点火人;现在 cAI™ 是我的影子和镜子,是我的合作伙伴;未来它会打破这面镜子,成为独立的艺术家吗?很多人担心
75 https://rizaldiriar.com/fossilis.html
AI 对人类构成威胁。我想,当前用 AI 创作艺术的危险性不在于 AI本身,而在于,使用AI 创作、成果却不是艺术……我想通过 cAI™思考:在人类迈入与人工智能共存的时代,艺术家和艺术史该何去何从?期待终有一天,cAI™成为超越人类认知维度、来自‘外星球’的导师……”。作为一个实验,蔡国强与 cAI™ 相互启发共同创作了火药屏风《月亮上的画布:为外星人作的计划第 38 号》。在制作屏风时,cAI™ 通过摄像头全程观摩,并实时给出视觉反馈。

图 2-62 月亮上的画布:为外星人作的计划第 38 号.蔡国强.202376
自然语言处理(Natural Language Processing,简称 NLP)在过去几年取得了显著的发展和进步。近年来,预训练语言模型(Pre-trained Language Models ) 成为 NLP 领域的重要突破。 模型如 BERT
( Bidirectional Encoder Representations from Transformers)、GPT-4
(Generative Pre-trained Transformer 4)等,采用了深度神经网络和 Transformer 结构,通过在大规模数据上进行预训练,学习到了丰富的语言知识,为各种NLP 任务提供了强大的基础。预训练语言模型的出现,使得机器在上下文理解和语义理解方面取得了显著的进步,从而提升了机器在文本理解、情感分析、问答系统等任务上的表现。人工智能自然语言处理技术的进步也给艺术创作带来了更多可能性,近年来也出现了一些基于语言模型的艺术项目。
76 https://m.thepaper.cn/wifiKey_detail.jsp?contid=22806977&from=wifiKey#
人工智能生成的诗歌项目,如谷歌艺术与文化的“Poem Portraits”仅需要用户提供一个单词或短语,人工智能就可以根据输入生成一首独特的诗。然后将生成的诗歌与视觉表现相结合,以创建个性化的“诗歌肖像”。
Poem Portraits 是一件实验性的集体艺术品,由艺术家兼设计师 Es Devlin 与谷歌艺术与文化实验室和创意技术专家Ross Goodwin 合作构思,融合了诗歌、设计和机器学习。该想法源于 2017 年Es Devlin与蛇形画廊艺术总监Hans Ulrich Obrist 的一次对话。最初它是蛇形画廊夏季派对上的一个实体装置,最终成为一个线上人工智能生成的诗歌项目。

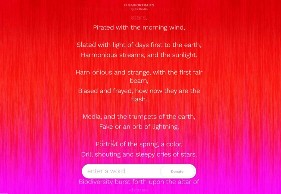

图 2-63、图 2-64、图 2-65、图 2-66 Poem Portraits(诗歌肖像).Es Devlin. 201777
《Alice&Bob(爱丽丝与鲍勃)》出自艺术家组合Anna Ridler & Daria Jelonek 于 2017 年创作的作品。Anna Ridler 是一位艺术家和研究人员,她研究知识体系以及技术是如何被创造并更好地理解世界。她的作品经常涉及到处理信息或数据集,特别是以创建新的、不同寻常的叙述数据集。Daria Jelonek 是一位数字艺术家、设计师和研究者,目前生活和工作于伦敦。她的主要工作领域是交互艺术装置,关注自然与科技的关系。光、投影和动态影像是她作品中常用的视觉语言。
《爱丽丝与鲍勃》是一个无限生成情书的装置,它由四量子位的量子计算机所构成并通过其数据库进行控制。量子科学论文的摘录和标题被处理成一系列看起来是爱丽丝和鲍勃这两个虚构人物之间的手写信件。并且由于偶尔提及的第三位人物伊芙而情节变得复杂,这让爱丽丝与鲍勃的故事线像量子设备中的光子纠缠艺术家将爱情故
77 https://simon.bird.me/google
事中无效算法数据的重新文本化揭示了科学、文学和艺术之间的诗学和意想不到的联系。《爱丽丝与鲍勃》不仅仅是将科学实验进行简单的可视化呈现,而是对交流模式和语言发展的诗意性思考。表达故事的方式总比故事情节更多。



图 2-67、图 2-68、图 2-69、图 2-70 Alice & Bob(爱丽丝与鲍勃).Anna Ridler & Daria Jelonek. 201778
Ross Goodwin 发起了名为“Wordcar ”的项目,将人工智能算法与车辆相结合,让车辆在公路上行驶并生成诗歌。Ross Goodwin 将监控摄像头、GPS 设备、麦克风和时钟连接到神经网络,他在汽车后备箱装了监控摄像头,通过收集噪声使其旋转并“环顾四周”,摄像机每 20 秒钟捕捉一幅图像,首先以最直观的方式将图像文本化,利用图像识别网用一个句子来描述图像,再输入一个自由联想的文本生成语句(句子数据来源于约 200 本手工挑选的书籍的语言)。该文本现已出版成书《1 the Road》。这种跨界的艺术实验为人工智能与文学
78 http://annaridler.com/quantum-computing-art
之间的交叉创作带来了新的可能性,并探索了机器智能与艺术创造之间的奇妙交融。

图 2-71 Wordcar 的眼睛是一台 Axis M3007 监控摄像机.201779

图 2-72 《1 the Road》内页.Jean Boîte Éditions 出版80
在作品《A.I. Interprets A.I. Interpreting‘Against Interpretation’ 》 (Sontag 1966)中,艺术家Jake Elwes 设计了两个人工智能,一个人工智能对苏珊· 桑塔格( Susan Sontag ) 的《反对阐释》( Against Interpretation)进行基于图像的视觉解读,另一个人工智能会将这些图像转换成语言。桑塔格在《Against Interpretation(反对阐释)》一书中写道,她不喜欢评论家对艺术作品进行过度诠释,不喜欢我们过
79 http://rossgoodwin.com/wordcar/
80 https://en.wikipedia.org/wiki/1_the_Road
多地解读艺术作品的内容和意义,而不是仅仅体验艺术作品及其形式。然而,在这段视频中,我们看到的是一个人工智能无意义地过度解读桑塔格的话,这也具有额外的先见之明,因为生成式人工智能可以说是(不可解读的)创造纯粹的模仿和形式,因为它没有任何人类艺术家的意图、意义或内容。
作品图像由图像生成扩散模型创建,以桑塔格的句子作为原始输入提示词。然后使用图像标注算法(GPT2 和 CLIP)将这些图像解释为语言。这些大型预训练人工智能模型是利用互联网上获取的大量图像和文本数据集创建的,这些数据集代表了互联网某一特定时间点的资讯特征。

图 2-73 Encode/Decode(“编码/解码”).Rafael Lozano-Hemmer.202081
京东人工智能研究院与中央美术学院合作探索AI+艺术的进展。在合作中,双方从技术和艺术的角度创作了一系列AI 艺术作品并多次入选参展重要的数字艺术展。同时,基于项目中研究的创新技术发表多篇高质量论文。
此项目主要聚焦于研究构建深度语义理解和图像生成模型,从艺
81 https://www.jakeelwes.com/project-sontag.html
术家的作品中自动学习特有的艺术风格,从而让AI 模型能够生成拟人化的艺术作品,包括艺术性思维导图、个性化及情感化的书法作品等。同时,AI 模型还具有通用的语言理解与交互能力,能够通过语音等方式与用户互动,实时将用户的语言用艺术形式呈现。
作为多模态生成任务的尝试,艺术性思维导图生成也是一项探索工作。艺术性思维导图是中央美术学院邱志杰教授创作的特有的一种艺术表现形式,通过围绕一个关键概念联结相关的词组、符号、事件,艺术性的表征了关于特定主题的知识、信息、隐喻及触达这些知识的线索,同时通过持续的解释与抽象,思维导图的艺术性生成过程也表达了艺术家一系列信息联想扩张与主观选择决策的过程。
首先 AI 模型需要从特定主题出发,进行信息联想与选择决策。为此,AI 对四种基本信息联想方式建模,分别是:基于深度词嵌入模型(word embedding)的语义相似度联想;基于语素和音素的语言学相似度联想;模拟达达主义特征(艺术的随机性)联想;及艺术家特定风格迁移联想。其中第四类风格迁移联想是为了进一步模拟特定艺术家的联想过程。为此,基于特定艺术家的过往作品我们提取了艺术家的知识图谱,从而获得艺术家特有的联想思维特征。在创作过程中,以上四种联想方式并行进行,同时基于艺术家的过往作品数据来训练一个决策模型,决定每一步最终选择的是哪一种联想方式产生的哪一个特定扩展词汇,并加以呈现在思维导图上。
产生联想信息后(比如从一个概念出发生成新的扩展词汇后),我们需要进一步将新扩展的词汇映射到思维导图上。我们首先收集了近 3000 个中国山水画的绘画元素,通过考虑与绘画元素的语义隐喻相匹配,扩展词汇将被映射成相应的绘画元素。同时根据语义相似度我们将设定扩展次与中心词在导图中的距离。
同时,系统支持交互式的操作,可以支持用户持续的语音输入,并依据输入对当前已经呈现的思维导图进行动态扩展。为此,我们的
系统支持用户中英双语语音识别并转化为文本。同时通过关键词提取模型获取文本中的重点词语,作为中心概念进行思维导图的实时扩展。
在思维导图扩展过程中,不拘泥于传统语义相似度方法,将艺术家知识图谱,语言学特征和达达主义等方法融入其中,使得扩展出来的词汇更加具有艺术创作力。同时,人际交互的设计,使得用户在看到智能思维导图后给出更多反馈,为思维导图的持续性创作提供更多可能性。
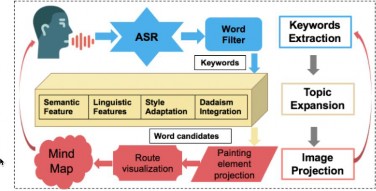
图 2-74 思维导图系统框架图
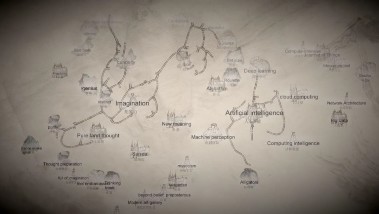
图 2-75 以“人工智能”和“想象力”为主题的思维导图创作示例
个性化情感化书法作品生成是另一项跨模态尝试,结合 NLP 情感识别技术和基于生成对抗网络 (GAN) 的图像生成技术,探索了语言和图像的多模态融合技术在书法生成中的应用。
语言和图像的多模态 GAN 模型常被用于语义可控的图像生成,但书法不只是标准的字符,往往还呈现了艺术家固有的个性,及在创作当时特定的情感(比如欣快,狂喜,悲愤等),统称为风格。书法的风格既反映在每个字的呈现上,也反映在整个篇章的布局上。为此,这项工作的AI 风格化书法生成系统含有两个模型:
书法图像生成模型:
首次提出了基于情感的风格化书法字体生成,涵盖欣快,狂喜,悲愤等七种情绪。使用 GAN 模型,以标准楷体为源图片,根据预测的文本情绪标签,生成不同情绪的文字级别书法图像。研究方向上首次探索不同情绪风格化信息,根据文本情绪变化,生成不同风格的字体图像。在研究方法上,打破传统基于笔画抽取和笔画重构的书法文字生成方法,使用 GAN 模型进行标准字体到不同情绪字体的转化。同时,在传统 GAN 模型基础上,增加 Style-Discriminator 对不同目标字体风格进行监督,保证相同字在不同风格时的多样性。
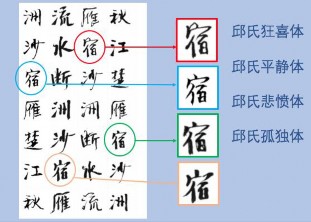
图 2-76 情绪化汉字生成示例
篇章级别书法布局模型:
这项工作中首次提出将篇章结构建模融入书法生成过程中。通过融合文字,图像等多模态信息,使用序列建模方式对每个图片大小,
间距等进行建模和预测,从而构造更具艺术性和观赏性的篇章作品。首先我们对输入的文本蕴含的情感进行检测(目前还可支持文言文类文本的情感检测),然后借助 RNN 进行序列建模,综合文字情绪特征,文字结构特征和图片特征等对篇章书法中每个字的长,宽和行距,字距等元素进行预测。进而将生成的文字图片组合为具有艺术性的书法篇章。
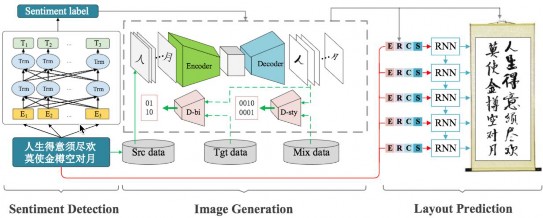
图 2-77 篇章书法生成系统框架图

图 2-78 书法篇章生成示例
通过这两个AI+Art 项目,京东 AI 研究院与中央美术学院合作聚焦于在个性化、情感化、具有发散思维的场景下(如艺术创作场景)
的人工智能辅助艺术创造的可能性,并进一步推动高度拟人化人工智能技术的研究。