2.3 条件概率分布与随机变量的独立性⚓︎
2.3 条件概率分布与随机变量的独立性⚓︎
0.1. 1 条件概率分布的概念⚓︎
一个随机变量或向量 \(X\) 的条件概率分布, 就是在某种给定的
- 70 • 条件之下, \(X\) 的概率分布.一如以前我们在讨论条件概率时所指 出的,任何事件的概率都是 “有条件的”, 即与这事件联系着的试验 的条件, 如骰子是均匀的立方体且抛郑的高度是足够大之类. 以 此,任何随机变量或向量的分布, 也无不是在一定条件下. 但此处 所谈的条件分布, 是在试验中所规定的“基本” 条件之外再附加的 条件. 它一般采取如下的形式: 设有两个随机变量或向量 \(X, Y\),在 给定了 \(Y\) 取某个或某些值的条件下,去求 \(X\) 的条件分布.
例如, 考虑一大群人, 从其中随机抽取一个, 分别以 \(X_{1}\) 和 \(X_{2}\) 记其体重和身高, 则 \(X_{1}, X_{2}\) 都是随机变量, 它们都有一定的概率 分布. 现在如限制 \(1.7 \leqslant X_{2} \leqslant 1.8\) (米), 在这个条件下去求 \(X_{1}\) 的 条件分布, 这就意味着要从这一大群人中把其身高在 1.7 米和 1.8 米的那些人都挑出来, 然后在挑出的人群中求其体重的分布. 容易想像, 这个分布与不设这个条件的分布 (无条件分布) 会很不 一样.例如,在条件分布中体重取大值的概率会显著增加.
从这个例子也看出条件分布这个概念的重要性. 在本例中, 弄 清了 \(X_{1}\) 的条件分布随 \(X_{2}\) 之值而变化的情况, 就能了解身高对体 重的影响在数量上的表述. 由于在许多问题中有关的变量往往是 彼此有影响的, 这使条件分布成为研究变量之间的相依关系的一 个有力工具. 这一点以后在第六章中还要作更深入的发挥.
0.2. 2 离散型随机变至的条件概率分布⚓︎
这个情况比较简单,实际上无非是第一章讲过的条件概率概 念在另一种形式下的重复. 设 \(\left(X_{1}, X_{2}\right)\) 为一个二维离散型随机向 量, \(X_{1}\) 的全部可能值为 \(a_{1}, a_{2}, \cdots ; X_{2}\) 的全部可能值为 \(b_{1}, b_{2}, \cdots\), 而 \(\left(X_{1}, X_{2}\right)\) 的联合概率分市为
现考虑 \(X_{1}\) 在给定 \(X_{2}=b_{j}\) 的条件下的条件分布,那无非是要找条 件概率 \(P\left(X_{1}=a \mid X_{2}=b_{j}\right)\) ,依条件概率的定义,有
再据公式 (2.8)( \(n=2\) 的情况), 有 \(P\left(X_{2}=b_{j}\right)=\sum_{k} p_{k j}\). 于是 类似地有
例 3.1 再考虑例 2.6. 据公式 (3.1) 和 (3.2), 不难算出在给 定 \(X_{2}\) 时 \(X_{1}\) 的条件分布, 与给定 \(X_{1}\) 时 \(X_{2}\) 的条件分布. 例如, 在 给定 \(X_{2}=0\) 时有
例 3.2 设 \(\left(X_{1}, X_{2}, \cdots, X_{n}\right)\) 服从多项分布 \(M\left(N ; p_{1}, \cdots\right.\), \(\left.p_{n}\right)\). 试求在给定 \(X_{2}=k_{2}\) 的条件下, \(X_{1}\) 的条件分布.
先计算概率 \(P\left(X_{1}=k_{2}, X_{2}=k_{2}\right)\). 这里假定 \(k_{1}, k_{2}\) 都是非负 整数, 且 \(k_{1} \leqslant N-k_{2}\). 按 \((2.3)\) 式, 有
这里 \(\sum_{k_{3}, \cdots, k_{n}}^{\prime}\) 表示求和的范围为 \(k_{3}, \cdots, k_{n}\) 都是非负整数, 且 \(k_{3}+\cdots\)
其中
由于 \(p_{3}^{\prime}+\cdots+p_{n}^{\prime}=1\), 考虑到上式求和的范围及多项展开式 (2.4), 即知 \(C=1\), 因此
再根据例 \(2.7, X_{2}\) 的分布就是二项分布 \(B\left(N, p_{2}\right)\). 因此
由此可知: 在给定 \(X_{2}=k_{2}\) 的条件下, \(X_{1}\) 的条件分布就是分布 \(B\left(N-k_{2}, p_{1} /\left(1-p_{2}\right)\right)\).
0.3. 3 连续型随机变是的条件分布⚓︎
设二维随机向量 \(X=\left(X_{1}, X_{2}\right)\) 有概率密度函数 \(f\left(x_{1}, x_{2}\right)\). 我们先来考虑在限定 \(a \leqslant x_{2} \leqslant b\) 的条件下, \(X_{1}\) 的条件分布. 有
\(X_{2}\) 的边缘分布的密度函数 \(f_{2}\) 由 \((2.10)\) 给出. 有
由此得到
这是 \(X_{1}\) 的条件分布函数. 对 \(x_{1}\) 求导数,得到条件密度函数为
更有兴趣的是 \(a=b\) 的情况, 即在 \(X_{2}\) 给定等于一个值之下, \(X_{1}\) 的条件密度函数. 这不能通过直接在 (3.3) 中令 \(a=b\) 得出, 但 可用极限步骤:
这就是在给定 \(X_{2}=x_{2}\) 的条件下, \(X_{1}\) 的条件密度函数. 此式当然 只有在 \(f_{2}\left(x_{2}\right)>0\) 时才有意义. 在上述取极限的过程中, 还得假 定函数 \(f_{2}\) 在 \(x_{2}\) 点连续, 及 \(f\left(x_{1}, t_{2}\right)\) 作为 \(t_{2}\) 的函数, 在 \(t_{2}=x_{2}\) 处 连续. 然而, 用高等概率论的知识, 可以在没有这种连续的假定下 证明 (3.4).
(3.4) 式可改写为
就是说: 两个随机变量 \(X_{1}\) 和 \(X_{2}\) 联合概率密度, 等于其中之一的 概率密度乘以在给定这一个之下另一个的条件概率密度. 这个公 式相应于条件概率的公式 \(P(A B)=P(B) P(A \mid B)\). 除 (3.5) 外, 当然也有
其中 \(f_{1}\) 为 \(x_{1}\) 的边缘密度, 而
则是在给定 \(X_{1}=x_{1}\) 的条件下, \(X_{2}\) 的条件密度. 这些公式反映的 实质可推广到任意多个变量的场合: 设有 \(n\) 维随机向量 \(\left(X_{1}, \cdots\right.\), \(\left.X_{n}\right)\), 其概率密度函数为 \(f\left(x_{1}, \cdots, x_{n}\right)\). 则
其中 \(\mathrm{g}\) 是 \(\left(X_{1}, \cdots, X_{k}\right)\) 的概率密度,而 \(h\) 则是在给定 \(X_{1}=x_{1}, \cdots\), \(X_{k}=x_{k}\) 的条件下, \(X_{k+1}, \cdots, X_{n}\) 的条件概率密度. (3.8) 可视为 (3.6) 的直接推广, 又可视为 \(h\left(x_{k+1}, \cdots, x_{n} \mid x_{1}, \cdots, x_{k}\right)\) 的定义.
例 3.3 设 \(\left(X_{1}, X_{2}\right)\) 服从二维正态分布 \(N\left(a, b, \sigma_{1}^{2}, \sigma_{2}^{2}, \rho\right)\). 求在给定 \(X_{1}=x_{1}\) 的条件下, \(X_{2}\) 的条件密度函数 \(f_{2}\left(x_{2} \mid x_{1}\right)\).
利用公式 (3.7), (2.7) 和 (2.12), 经过简单的计算, 得出
这正是正态分布 \(N\left(b+\rho \sigma_{2} \sigma_{1}^{-1}\left(x_{1}-a\right), \sigma_{2}^{2}\left(1-\rho^{2}\right)\right)\) 的概率密度 函数 (注意在 (3.9) 式中, \(x_{1}\) 当常数看). 因此,正态变量的条件分 布仍为正态, 这是正态分布的一个重要性质.
如我们在图 \(2.2 b\) 中所显示的, 正态分布 \(N\left(\mu, \sigma^{2}\right)\) 关于 \(\mu\) 点一 对称, \(\mu\) 就是分布的中心位置,对正态分布 (3.9), 这个中心位置在
处,由这里可以看出 \(\rho\) 刻画了 \(X_{1}, X_{2}\) 之间的相依关系. 其解释如 下: 若 \(\rho>0\), 则随着 \(x_{1}\) 的增加, \(X_{2}\) (在 \(X_{1}=x_{1}\) 之下) 的条件分布 的中心点 \(m\left(x_{1}\right)\) 随 \(x_{1}\) 的增加而增加. 可以看出: 这意味着当 \(x_{1}\) 增加时, \(X_{2}\) 取大值的可能性增加, 即 \(X_{2}\) 有随着 \(X_{1}\) 的增长而增长 的倾向 (如体重与身高的关系那样). 反之, 若 \(\rho<0\), 则 \(X_{2}\) 有随着 \(X_{1}\) 增长而下降的倾向. 由于这个原因, 通常把 \(\rho>0\) 的情况称为 “正相关”, 而 \(\rho<0\) 的情况称为 “负相关”. 这一点在下一章中还要 谈到。
把 (3.5) 两边对 \(x_{2}\) 积分, 得
这个公式可解释为: \(X_{1}\) 的无条件密度 \(f_{1}\left(x_{1}\right)\), 是其条件密度 \(f_{1}\) \(\left(x_{1} \mid x_{2}\right)\) 对“条件” \(x_{2}\) 的平均. 更确切地说, 是按其概率大小为权的 加权平均,因为, \(f_{2}\left(x_{2}\right) \mathrm{d} x_{2}\) 正是 \(X_{2}\) 在 \(x_{2}\) 附近 \(\mathrm{d} x_{2}\) 这么长的区 间内的概率. 从直观上看这应当是很自然的. 比如说, \(\left(X_{1}, X_{2}\right)\) 代 表一大群人中随机抽出的一个人的体重和身长, \(X_{1}\) (体重)有其 (无条件)分布, 这可以看作为各种不同的身高综合之后所呈现的 分布, 而不同于固定身长 \(X_{2}=x_{2}\) 时的条件分布. 但把各种身长时 体重的条件分布进行平均, 也就实现了上述综合, 即得到无条件分 布. 公式(3.11) 正好从数学上反映了这种综合 (或平均) 的过程.
还要注意: 公式 (3.11) 也可以看作是全概率公式 (第一章) (3.17) 在概率密度这种情况下的表现形式. 在这里, \(f_{1}\left(x_{1}\right)\) 相当 于全概率公式中的 \(P(A), f_{1}\left(x_{1} \mid x_{2}\right)\) 相当于条件概率 \(P\left(A \mid B_{i}\right)\), 而 (3.11) 中的积分, 正好相当于 (3.17) 式中的以 \(P\left(B_{i}\right)\) 为权的加 权和。
由此可见, 在学习概率论时, 不能光是形式地看待一些分析公 式, 更重要的是要分析其概率意义及直观意义, 这样才能加深理 解. 上述对公式 (3.11) 的分析是一个例子. 再如, 在例 3.3 中我们 用形式推导很容易得出了条件密度 (3.9) 式. 只看这形式推导, 你 可能地觉得这里没有什么特别值得注意的地方. 但经过分析 (3.10) 式中 \(\rho\) 的作用, 再辅之以体重身高这个实例, 我们就领悟 到了 \(\rho\) 作为刻画二者的相依性的作用, 理解就深一层了, 在下一 章中我们还要进一步讨论 (3.9) 所反映出的其他概率含义.
0.4. 4 随机变量的独立性⚓︎
先考虑两个变量 \(X_{1}, X_{2}\) 的情况,并设 \(\left(X_{1}, X_{2}\right)\) 为连续型. 如 前, 分别以 \(f\left(x_{1}, x_{2}\right), f_{1}\left(x_{1}\right), f_{2}\left(x_{2}\right), f_{1}\left(x_{1} \mid x_{2}\right), f_{2}\left(x_{2} \mid x_{1}\right)\) 记 联合、边缘与条件概率密度.
一般, \(f_{1}\left(x_{1} \mid x_{2}\right)\) 是随 \(x_{2}\) 的变化而变化的,这反映了 \(X_{1}\) 与 \(X_{2}\) 在概率上有相依关系的事实, 即 \(X_{1}\) 的 (条件) 分布如何, 取决 于另一变量之值.
如果 \(f_{1}\left(x_{1} \mid x_{2}\right)\) 不依赖于 \(x_{2}\), 因而只是 \(x_{1}\) 的函数,暂记为 \(g\left(x_{1}\right)\),则表示 \(X_{1}\) 的分布情况与 \(X_{2}\) 取什么值完全无关, 这时就 称 \(X_{1}, X_{2}\) 这两个随机变量 (在概率论意义上) 独立. 这概念与事件 独立的概念完全相似.
因此, \(X_{1}\) 的无条件密度 \(f_{1}\left(x_{1}\right)\), 就等于其条件密度 \(f_{1}\left(x_{1} \mid x_{2}\right)\), 这也可取为独立性的定义.
再次,把 \(f_{1}\left(x_{1}\right)=f_{1}\left(x_{1} \mid x_{2}\right)\) 代人 \((3.5)\), 得
即 \(\left(X_{1}, X_{2}\right)\) 的联合密度, 等于其各分量的密度之积. 这也可取作为 \(X_{1}, X_{2}\) 独立的定义 (此式相应于第一章 (3.7) 式), 比之上述定义, 它有其优越性: 一是其形式关于两个变量对称,二是它总有意义, 而在用条件密度去定义时, 可能碰到条件密度在个别点无法定义 (分母为 0 ) 的情况.
这个形式的另一个好处是它可以直接推广到任意多个变量的 情形. 我们就把它取为一般情况下的正式定义:
定义 3.1 设 \(n\) 维随机向量 \(\left(X_{1}, \cdots, X_{n}\right)\) 的联合密度函数为 \(f\left(x_{1}, \cdots, x_{n}\right)\), 而 \(X_{i}\) 的 (边缘) 密度函数为 \(f_{i}\left(x_{i}\right), i=1, \cdots, n\). 如 果
就称随机变量 \(X_{1}, \cdots, X_{n}\) 相互独立或简称独立.
变量独立性的概念还可以从另外的角度去考察. 按前面的分 析, 它含有这种意思: 如果 \(X_{1}, \cdots, X_{n}\) 独立,则各变量取值的概率 如何, 毫不受其他变量之影响, 因此,若考察 \(n\) 个事件
则因各事件只涉及一个变量, 它们应当是相互独立的事件,我们可 以把这个要求取为变量 \(X_{1}, \cdots, X_{n}\) 独立的定义.下面的定理证明, 这与定义 3.1 是等价的, 即同一件事的两种不同的说法.
定理 3.1 如果连续变量 \(X_{1}, \cdots, X_{n}\) 独立时, 则对任何 \(a_{i}<\) \(b_{i}, i=1, \cdots, n\), 由 (3.14) 定义的 \(n\) 个事件 \(A_{1}, \cdots, A_{n}\) 也独立.
反之, 若对任何 \(a_{i}<b_{i}, i=1, \cdots, n\), 事件 \(A_{1}, \cdots, A_{n}\) 独立, 则 变量 \(X_{1}, \cdots, X_{n}\) 也独立.
证 先设 \(X_{1}, \cdots, X_{n}\) 独立, 因而 (3.13) 成立. 为证事件 \(A_{1}\), \(\cdots, A_{n}\) 独立, 按第一章定义 3.3 , 必须对任何 \(i_{1}, \cdots, i_{m}\left(1 \leqslant i_{1}<\right.\) \(\left.i_{2}<\cdots<i_{m} \leqslant n\right)\) 去证明
为书写简单计, 我们对 \(i_{1}=1, i_{2}=2, \cdots, i_{m}=m\) 来证此式, 这不影 响普遍性.按联合分布密度的定义 (2.5)式,有
这证明了所要的结果.
另一方面,若对任何 \(a_{i}<b_{i}, i=1, \cdots, n\), (3.14) 中的 \(n\) 个事 件独立, 则取 \(A_{i}=\left\{-\infty<X_{i} \leqslant x_{i}\right\}, i=1, \cdots, n\), 由
即得
上式两边依次对 \(x_{1}, x_{2}, \cdots, x_{n}\) 取偏导数(即作 \(\partial^{n} / \partial x_{1} \partial x_{2} \cdots \partial x_{n}\) ), 即得 (3.13) 式, 因而证明了 \(X_{1}, \cdots, X_{n}\) 独立.
下面再提出两个有关独立性的有用的结果.
定理 3.2 若连续型随机向量 \(\left(X_{1}, \cdots, X_{n}\right)\) 的概率密度函数 \(f\left(x_{1}, \cdots, x_{n}\right)\) 可表为 \(n\) 个函数 \(g_{1}, \cdots, g_{n}\) 之积, 其中 \(g_{i}\) 只依赖于 \(x_{i}\), 即
则 \(X_{1}, \cdots, X_{n}\) 相互独立, 且 \(X_{i}\) 的边缘密度函数 \(f_{i}\left(x_{i}\right)\) 与 \(g_{i}\left(x_{i}\right)\) 只 相差一个常数因子.
证 按 (2.11) 式, 知 \(X_{1}\) 的密度函数为
其中 \(C_{1}\) 为常数. 同法证明 \(X_{i}\) 的密度函数 \(C_{i} g_{i}\left(x_{i}\right)\).
因此 \(g_{i}\left(x_{i}\right)=C_{i}^{-1} f_{i}\left(x_{i}\right)\), 其中 \(f_{i}\) 是 \(x_{i}\) 的密度函数. 以此代 人(3.15), 知 \(f\left(x_{1}, \cdots, x_{n}\right)=C_{1}^{-1} C_{2}^{-1} \cdots C_{n}^{-1} f_{1}\left(x_{1}\right) \cdots f_{n}\left(x_{n}\right)\). 由 此式两边对 \(x_{1}, \cdots, x_{n}\) 的积分都为 1 , 知 \(C_{1}^{-1} C_{2}^{-1} \cdots C_{n}^{-1}=1\), 因而 \(f\left(x_{1}, \cdots, x_{n}\right)=f_{1}\left(x_{1}\right) \cdots f_{n}\left(x_{n}\right)\). 按定义 (3.1), 知 \(X_{1}, \cdots, X_{n}\) 独 立.
定理 3.3 若 \(X_{1}, \cdots, X_{n}\) 相互独立, 而
则 \(Y_{1}\) 和 \(Y_{2}\) 独立.
这个定理直观上的意义很明白: 因为 \(X_{1}, \cdots, X_{n}\) 相互独立, 把 它分成两部分 \(X_{1}, \cdots, X_{m}\) 及 \(X_{m+1}, \cdots, X_{n}\), 二者没有关系. 因为 \(Y_{1}, Y_{2}\) 分别只与前者和后者有关, 它们之间也不应有相依关系. 证明细节也不难写出, 在此从略了.
以上讨论的是关于连续型变量的独立性, 至于离散型则更为 简单.
定义 3.2 设 \(X_{1}, \cdots, X_{n}\) 都是离散型随机变量. 若对任何常 数 \(a_{1}, \cdots, a_{n}\), 都有
则称 \(X_{1}, \cdots, X_{n}\) 相互独立.
所有关于独立性的定理,如定理 3.1-3.3, 全都适用于离散 型. 唯一的变动是: 凡是在这些定理中提到“密度函数” 的地方, 现 在要改为“概率函数”.
例 3.4 设 \(\left(X_{1}, X_{2}\right)\) 服从二维正态分布 \(N\left(a, b, \sigma_{1}^{2}, \sigma_{2}^{2}, \rho\right)\). 由其联合密度函数 \(f\left(x_{1}, x_{2}\right)\) 的形式 (2.7) 看出 : 当且仅当 \(\rho=0\) 时, \(f\left(x_{1}, x_{2}\right)\) 才可以表为两个边缘密度 \(f_{1}\left(x_{1}\right)\) 和 \(f_{2}\left(x_{2}\right)\) 之积. 因 此,当且仅当 \(\rho=0\) 时, \(X_{1}\) 和 \(X_{2}\) 独立. 这进一步反映了我们以前 提及的一点事实: \(\rho\) 这个参数与 \(X_{1}, X_{2}\) 的相依性有关.
例 3.5 考虑例 2.4 的随机向量 \(\left(X_{1}, X_{2}\right)\). 据例 2.9 的结果, 不难知道: \(X_{1}, X_{2}\) 不为独立.
与事件的独立性一样, 在实际问题中, 变量的独立性往往不是 从其数学定义去验证出来的. 相反, 常是从变量产生的实际背景判 断它们独立 (或者其相依性很微弱因而可近似地认为是独立), 然 后再使用独立性定义中所赋予的性质和独立性的有关定理. 例如, 一城市中两个相距较远的路段在一定时间内各自发生的交通事故 数,一个人的姓氏笔划与其智商. 在实际中, \(n\) 个变量 \(X_{1}, \cdots, X_{n}\) 的独立性通常是这样产生的: 有 \(n\) 个彼此无关联的试验 \(E_{1}, \cdots\), \(E_{n}\), 而 \(X_{i}\) 只依赖于试验 \(E_{i}\) 的结果. 形式上我们可以构作一个复 合试验 \(E=\left(E_{1}, \cdots, E_{n}\right)\), 以把这 \(n\) 个变量都包容在这个试验 \(E\) 之下. 这种观点在讲事件独立性时已提到过了.
然而, 在主要是理论的情况下, 需要直接借助于定义来验证变 量的独立性.举一个例子.
例 3.6 设 \(X_{1}, X_{2}\) 独立, 都服 从标准正态分布 \(N(0,1)\). 把点 \(\left(X_{1}, X_{2}\right)\) 的极坐标记为 \((R, \Theta)\), \(0 \leqslant R<\infty, 0 \leqslant \Theta<2 \pi\). 求证: \(R\) 和 \(\Theta\) 独立 (图 2.9).
取定 \(r_{0}>0,0<\theta_{0}<2 \pi\). 考虑 事件 \(B=\left\{0 \leqslant R \leqslant r_{0}, 0 \leqslant \Theta \leqslant \theta_{0}\right\}\). 由于 \(X_{1}, X_{2}\) 独立且各自的密度函
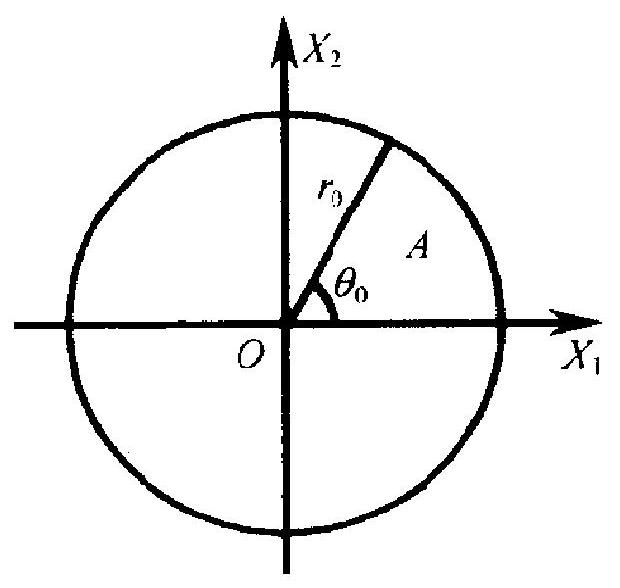 数分别为 \(\sqrt{2 \pi}^{-1} \cdot \mathrm{e}^{-x_{1}^{2} / 2}\) 和 \(\sqrt{2 \pi}^{-1}\). \(\mathrm{e}^{-x_{2}^{2} / 2}\), 由独立性定义 3.1 知 图 2.9 \(\left(X_{1}, X_{2}\right)\) 的联合密度为 \((2 \pi)^{-1} \exp \left(-\frac{1}{2}\left(x_{1}^{2}+x_{2}^{2}\right)\right)\). 因此, 按密 度函数的定义 (2.5)式, 有
数分别为 \(\sqrt{2 \pi}^{-1} \cdot \mathrm{e}^{-x_{1}^{2} / 2}\) 和 \(\sqrt{2 \pi}^{-1}\). \(\mathrm{e}^{-x_{2}^{2} / 2}\), 由独立性定义 3.1 知 图 2.9 \(\left(X_{1}, X_{2}\right)\) 的联合密度为 \((2 \pi)^{-1} \exp \left(-\frac{1}{2}\left(x_{1}^{2}+x_{2}^{2}\right)\right)\). 因此, 按密 度函数的定义 (2.5)式, 有
化为极坐标, 得
由这个等式直接看出: \((R, \Theta)\) 的概率密度函数就是 \((2 \pi)^{-1} \mathrm{e}^{-r^{2} / 2} r\) (当 \(0 \leqslant r<\infty, 0 \leqslant \theta<2 \pi\), 其他处为 0 ). 它是下述两个函数的乘 积:
按定理 3.2 , 即得知 \(R\) 与 \(\Theta\) 独立, 且 \(R\) 与 \(\Theta\) 的密度函数分别是 \(f_{1}(r)\) 和 \(f_{2}(\theta)\).
离散型变量独立性的一个重要例子涉及事件独立性与随机变 量独立性之间的关系。
例 3.7 设有 \(n\) 个事件 \(A_{1}, A_{2}, \cdots, A_{n}\). 针对每个事件 \(A_{i}\), 可 定义一随机变量 \(X_{i}\) 如下:
常把 \(X_{i}\) 称为事件 \(A\) 的指示变量或指示函数、示性函数 (indicator), 意思是其值“指示”了 \(A\) 是否发生. 这个写法表明: 事件可视 作随机变量的一种特例.
不难证明: 若事件 \(A_{1}, \cdots, A_{n}\) 独立, 则其指示变量 \(X_{1}, \cdots, X_{n}\) 独立. 反之亦成立. 证明是基于第一章的系 3.3 , 我们把细节留给 读者自己去完成.
利用指示变量的概念,可以对第一章系 3.2 后面那段话作出 统一而简洁的论证. 若事件 \(A_{1}, \cdots, A_{n}\) 独立, 而事件 \(B_{1}\) 取决于 \(A_{1}, \cdots, A_{m}\) (这意思是说:一旦知道了事件 \(A_{1}, \cdots, A_{m}\) 中每一个发 生与否, 就能定下 \(B_{1}\) 发生与否), 事件 \(B_{2}\) 取决于 \(A_{m+1}, \cdots, A_{n}\), 则 \(B_{1}\) 与 \(B_{2}\) 独立. 转到指示变量 : 分别以 \(X_{1}, \cdots, X_{n}\) 记 \(A_{1}, \cdots, A_{n}\) 的指示变量, 以 \(Y_{1}\) 和 \(Y_{2}\) 分别记 \(B_{1}\) 和 \(B_{2}\) 的指示变量. 按假定, 后者分别是 \(X_{1}, \cdots, X_{m}\) 与 \(X_{m+1}, \cdots, X_{n}\) 的函数:
由 \(A_{1}, \cdots, A_{n}\) 独立知随机变量 \(X_{1}, \cdots, X_{n}\) 独立. 再据定理 3.3, 即 知 \(Y_{1}\) 与 \(Y_{2}\) 独立, 因而事件 \(B_{1}\) 和 \(B_{2}\) 独立.
例 3.8 设 \(\left(X_{1}, \cdots, X_{n}\right)\) 服从多项分布 \(M\left(N ; p_{1}, \cdots, p_{n}\right)\), \(p_{i}>0, i=1, \cdots, n\). 对任何 \(u \neq v, X_{u}\) 和 \(X_{u}\) 不独立.
这个结论从直观上看至为明显: 按多项分布的定义有 \(X_{1}+\cdots\) \(+X_{n}=N\). 若 \(n>2\), 则虽然 \(X_{u}\) 并不足以唯一决定 \(X_{v}\), 但二者有 关. 例如, 当 \(X_{u}\) 取很大的值时, \(X_{u}\) 取大值的可能性就降低. 这说 明: \(X_{v}\) 在给定 \(X_{u}\) 之下的条件分布, 取决于 \(X_{u}\) 的给定值, 因而不 符合独立性的要求. 形式的证明也不难作出,留给读者去完成.
评论
登录github的账号后,可以直接在下方评论框中输入。
如果想进行更详细的讨论(如排版、上传图片等),选择一个反应后并点击上方的文字,进入论坛页面。