3.1 数学期望(均值)与中位数⚓︎
第三章 随机变量的数字特征⚓︎
在前章中,我们较仔细地讨论了随机变量的概率分布,这种分 布是随机变量的概率性质最完整的刻画. 而随机变量的数字特征, 则是某些由随机变量的分布所决定的常数, 它刻画了随机变量 (或 者说,刻画了其分布)的某一方面的性质.
例如,考虑某种大批生产的元件的寿命. 如果知道了它的概率 分布, 就可以知道寿命在任一指定界限内的元件百分率有多少, 这 对该种元件寿命状况提供了一幅完整的图景.如下文将指出的, 根 据这一分布就可以算出元件的平均寿命 \(m, m\) 这个数虽则不能对 寿命状况提供一个完整的刻画, 但却在一个重要方面, 且往往是人 们最为关心的一个方面,刻画了元件寿命的状况,因而在应用上有 极重要的意义. 类似的情况很多, 比如我们在了解某一行业工人的 经济状况时, 首先关心的恐怕会是其平均收入, 这给了我们一个总 的印象. 至于收人的分布状况, 除非为了特殊的研究目的, 倒反而 不一定是最重要的.
另一类重要的数字特征, 是衡量一个随机变量 (或其分布) 取 值的散布程度. 例如, 两个行业工人的平均收人大体相近, 但一个 行业中收人分配较平均: 大多数人的收入都在平均值上下不远处, 其“散布”小; 另一个行业则相反: 其收人远离平均值者甚多, 散布 较大, 这二者的实际意义当然很不同. 又如生产同一产品的两个工 厂, 各自的产品平均说来都能达到规格要求, 但一个厂波动小, 较 为稳定, 另一个厂则波动大, 有时质量超标准, 有时则低于标准不 少,这二者的实际后果当然也不同.
上面论及的平均值和散布度,是刻画随机变量性质的两类最 重要的数字特征. 对多维变量而言, 则还有一类刻画各分量之间的 关系的数字特征. 在本章中, 我们将就以上各类数字特征中, 举其 最重要者进行讨论.
1. 1 数学期望 (均值) 与中位数⚓︎
要说明这个名称的来由, 让我们回到第一章的例 1.1. 甲乙二 人赌技相同, 各出赌金 100 元, 约定先胜三局者为胜,取得全部 200 元. 现在甲胜 2 局乙胜 1 局的情况下中止,问賭本该如何分? 在那里我们已算出, 如果继续赌下去而不中止, 则甲有 \(3 / 4\) 的机会 (概率)取胜, 而乙胜的机会为 \(1 / 4\). 所以, 在甲胜 2 局乙胜 1 局这 个情况下, 甲能“期望”得到的数目, 应当确定为
而乙能“期望”得到的数目,则为
如果引进一个随机变量 \(X, X\) 等于在上述局面 (甲 2 胜乙 1 胜) 之 下, 继续赌下去甲的最终所得,则 \(X\) 有两个可能值: 200 和 0 ,其概 率分别为 \(3 / 4\) 和 \(1 / 4\). 而甲的期望所得, 即 \(X\) 的“期望”值, 即等于
\(X\) 的可能值与其概率之积的累加 这就是“数学期望” (简称期望) 这个名词的由来.这个名词源出赌 博,听起来不大通俗化或形象易懂,本不是一个很恰当的命名,但 它在概率论中已源远流长获得大家公认, 也就站住了脚根. 另一个 名词“均值”形象易懂,也很常用,将在下文解释.
1.1. 1 数学期望的定义⚓︎
先考虑一个最简单的情况.
定义 1.1 设随机变量 \(X\) 只取有限个可能值 \(a_{1}, \cdots, a_{m}\). 其概 率分布为 \(P\left(X=a_{i}\right)=p_{i}, i=1, \cdots, m\). 则 \(X\) 的数学期望, 记为 \(E(X)^{*}\) 或 \(E X\), 定义为
*E 是期望 Expectation 的缩写.
名词的来由已如前述. 数学期望也常称为 “均值”, 即 “随机变 量取值的平均值”之意, 当然这个平均, 是指以概率为权的加权平 均.
利用概率的统计定义, 容易给均值这个名词一个自然的解释. 假定把试验重复 \(N\) 次,每次把 \(X\) 取的值记下来,设在这 \(N\) 次中, 有 \(N_{1}\) 次取 \(a_{1}, N_{2}\) 次取 \(a_{2}, \cdots, N_{m}\) 次取 \(a_{m}\). 则这 \(N\) 次试验中 \(X\) 总共取值为 \(a_{1} N_{1}+a_{2} N_{2}+\cdots+a_{m} N_{m}\), 而平均每次试验中 \(X\) 取 值, 记为 \(\bar{X}\), 等于
\(N_{i} / N\) 是事件 \(\left\{X=a_{i}\right\}\) 在这 \(n\) 次试验中的频率. 按概率的统计定 义 (见第一章, 1.1 节), 当 \(N\) 很大时, \(N_{i} / N\) 应很接近 \(p_{i}\). 因此, \(\bar{X}\) 应接近于 (1.1) 式右边的量, 就是说, \(X\) 的数学期望 \(E(X)\) 不是别 的, 正是在大量次数试验之下, \(X\) 在各次试验中取值的平均.
很自然地,如果 \(X\) 为离散型变量, 取无穷个值 \(a_{1}, a_{2}, \cdots\),而 概率分布为 \(P\left(X=a_{i}\right)=p_{i}, i=1,2, \cdots\), 则我们仿照 (1.1), 而把 \(X\) 的数学期望 \(E(X)\) 定义为级数之和:
但当然, 必须级数收玫才行, 实际上我们要求更多, 要求这个级数 绝对收敛:
定义 1.2 如果
则称 (1.2) 式右边的级数之和为 \(X\) 的数学期望.
为什么不就要求 \((1.2)\) 右边收玫而必须要求 (1.3)? 这就涉及 级数理论中的一个现象: 如果某个级数, 例如 \(\sum_{i=1}^{\infty} a_{i} p_{i}\), 只是收玫 (称为条件收敛), 而其绝对值构成的级数 \(\sum_{i=1}^{\infty}\left|a_{i}\right| p_{i}\), 并不收敛, 则将这级数各项次序改排以后, 可以使它变得不收玫, 或者使它收 敛而其和等于事先任意指定之值. 这就意味着 (1.2)右边的和存在 与否, 等于多少, 与随机变量 \(X\) 所取之值的排列次序有关, 而 \(E(X)\) 作为刻画 \(X\) 的某种特性的数值, 有其客观意义, 不应与其值 的人为排列次序有关.
在连续型随机变量的情况, 以积分代替求和, 而得到数学期望 的定义:
定义 1.3 设 \(X\) 有概率密度函数 \(f(x)\). 如果
则称
为 \(X\) 的数学期望.
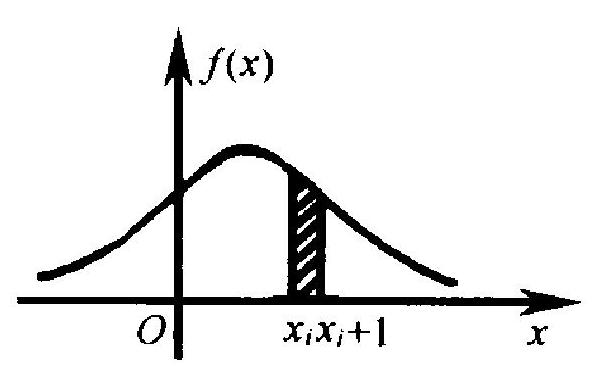
图 3.1
这个定义可以用离散化的方式 来加以解释. 如图 3.1, 在 \(x\) 轴上用 密集的点列 \(\left\{x_{i}\right\}\) 把 \(x\) 轴分成很多小 区间,长为 \(x_{i+1}-x_{i}=\Delta x_{i}\). 当 \(X\) 取 值于区间 \(\left[x_{i}, x_{i+1}\right)\) 内时, 可近似地 认为其值就是 \(x_{i}\). 按密度函数的定 义, \(X\) 取上述区间内之值的概率, 即 图中斜线标出部分的面积, 近似地为 \(f\left(x_{i}\right) \Delta x_{i}\). 用这个方式, 我们把原来的连续型随机变量 \(X\) 近似地 离散化为一个取无穷个值 \(\left\{x_{i}\right\}\) 的离散型变量 \(X^{\prime}, X^{\prime}\) 的分布为 \(P\left(X^{\prime}=x_{i}\right) \approx f\left(x_{i}\right) \Delta x_{i}\), 按定义 1.2 , 有
随着区间 \(\Delta x_{i}\) 愈分愈小, \(X^{\prime}\) 愈来愈接近 \(X\), 而上式右端之和也愈 来愈接近于 (1.5)式右边的积分, 这样就得出定义 1.3 . 至于要求 积分绝对收敛即 (1.4) 式, 其原因与定义 1.2 的情况有所不同, 在 此不能细论了.
例 1.1 设 \(X\) 服从波哇松分布 \(P(\lambda)\) (见第二章例 1.2), 则
这解释了波哇松分布 \(P(\lambda)\) 中参数 \(\lambda\) 的意义, 拿第二章例 1.2 的 情况来说, \(\lambda\) 就是在所指定的时间段中发生事故的平均次数.
例 1.2 设 \(X\) 服从负二项分布 (见第二章例 1.5 的 (1.11) 式), 则
为求这个和,我们要用到在第二章例 1.5 中指出过的负指数二项 展开式
两边对 \(x\) 求导,得
在上式中令 \(x=1-p\), 然后两边同乘 \(1-p\) 得到
而
\(p\) 愈小, 则此值愈大, 这是自然的:若事件 \(A\) 的概率 \(p\) 很小, 则等 待它出现 \(r\) 次的平均时间也就愈长, 当 \(r=1\) 时, 得到几何分布 (第二章 \((2.12)\) 式) 的期望为 \((1-p) / p\). 例 1.3 若 \(X\) 服从 \([a, b]\) 区间的均匀分布 (第二章例 1.9), 则
即期望为区间中点, 这在直观上很显然.
例 1.4 若 \(X\) 服从指数分布 (第二章例 1.7,(1.20) 式), 则
这个结果的直观解释曾在第二章例 1.7 中指出过.
例 1.5 设 \(X\) 服从正态分布 \(N\left(\mu, \sigma^{2}\right)\), 则
作变数代换 \(x=\mu+\sigma t\), 化为
上式右边第一项为 \(\mu\),第二项为 0 . 因此
这样, 我们得到了正态分布 \(N\left(\mu, \sigma^{2}\right)\) 中两个参数之一的 \(\mu\) 的解 释: \(\mu\) 就是均值, 这一点从直观上看很清楚, 因为 \(N\left(\mu, \sigma^{2}\right)\) 的密度 函数关于 \(\mu\) 点对称 (见第二章图 2.2b), 其均值自应在这个点.
因为数学期望是由随机变量的分布完全决定的,故我们可以 而且常常说某分布 \(F\) 的期望是多少, 某密度 \(f\) 的期望是多少等. 期望是通过概率分布而决定这个事实,可能会被理解为: 在任何应 用的场合, 当谈到某变量 \(X\) 的期望时, 必须知道其分布,这话不完 全确切. 在有些应用问题中, 人们难于决定有关变量的分布如何, 甚至也难于对之提出某种合理的假定,但有相当的根据 (经验的或 理论的)对期望值提出一些假定甚至有不少了解.例如,我们可能 比较确切地知道某行业工人的平均工资,而对工资的分布情况并 不很清楚. 另外, 当需要通过观察或试验取得数据以进行估计时, 去估计一变量的期望, 要比去估计其分布容易且更确切, 因为期望 只是一个数而分布 (或密度) 是一个函数. 以上所说对其他的数字 特征也成立. 在本书后面讲到数理统计学时将更明白这一点.
1.2. 2 数学期望的性质⚓︎
数学期望之所以在理论和应用上都极为重要,除了它本身的 含义(作为变量平均取值之刻画) 外, 还有一个原因, 即它具有一些 良好的性质, 这些性质使得它在数学上很方便. 本段就是讨论这个 问题.
定理 1.1 若干个随机变量之和的期望, 等于各变量的期望 之和, 即
当然,这里要假定各变量 \(X_{i}\) 的期望都存在.
证 先就 \(n=2\) 的情况来证,若 \(X_{1}, X_{2}\) 为离散型,分别以 \(a_{1}\), \(a_{2}, \cdots\) 和 \(b_{1}, b_{2}, \cdots\) 记 \(X_{1}\) 和 \(X_{2}\) 的一切可能值, 而记其分布为
当 \(X_{1}=a_{i}, X_{2}=b_{j}\) 时, 有 \(X_{1}+X_{2}=a_{i}+b_{j}\). 故
先看第一项,据第二章 \((2.8)\) 式,有
所以,按定义 1.2 , 有
同理, (1.14) 右边第二项为 \(E\left(X_{2}\right)\). 这证明了所要结果.
若 \(\left(X_{1}, X_{2}\right)\) 为连续型, 以 \(f\left(x_{1}, x_{2}\right)\) 记其联合密度, 按第二章 (4.16) 式, 知 \(X_{1}+X_{2}\) 的密度函数为 \(l(y)=\int_{-\infty}^{\infty} f(x, y-x) \mathrm{d} x\). 故按定义 1.3 ,有
在里面那个积分作变数代换 \(y=x+t\), 得
按第二章 (2.9) 式, 知 \(\int_{-\infty}^{\infty} f(x, t) \mathrm{d} t\) 就是 \(X_{1}\) 的密度函数. 所以, (1.15)右边第一个积分等于
同理证明第二个积分为 \(E\left(X_{2}\right)\), 于是证得了所要的结果.
一般情况可用归纳的方式得到. 例如, 记 \(Y=X_{1}+X_{2}\), 有
等等. 定理 1.1 证毕.
定理 1.2 若干个独立随机变量之积的期望, 等于各变量的 期望之积:
当然,这里也要假定各变量 \(X_{i}\) 的期望都存在.
证 与定理 1.1 相似, 只须对 \(n=2\) 的情况证明即可. 先设 \(X_{1}, X_{2}\) 都为离散型, 其分布为 (1.13). 由独立性假定知 \(p_{i j}=\) \(P\left(X_{1}=a_{i}\right) P\left(X_{2}=b_{j}\right)\).
因为当 \(X_{1}=a_{i}, X_{2}=b_{j}\) 时有 \(X_{1} X_{2}=a_{i} b_{j}\), 故
如所欲证. 若 \(\left(X_{1}, X_{2}\right)\) 为连续型, 则因独立性, 其联合密度 \(f\left(x_{1}\right.\), \(\left.x_{2}\right)\) 等于各分量密度 \(f_{1}\left(x_{1}\right)\) 与 \(f_{2}\left(x_{2}\right)\) 之积, 故
细心的读者可能会注意到, 在后一段证明中我们是从公式
出发, 而这公式并非直接从期望的定义而来, 它也需要证明. 因此, 更严格的证法应如定理 1.1 那样, 先推导出 \(X_{1} X_{2}\) 的密度 \(g\), 计算 \(\int_{-\infty}^{\infty} x g(x) \mathrm{d} x\) 再通过积分变数代换. 这不难做到, 我们把它放在 习题里留给读者去完成 (习题 21).
读者也许还会问:在以上两个定理中,如果一部分变量为离散 型, 一部分为连续型, 结果如何? 答案是结论仍成立. 对乘积的情 况, 由于有独立假定, 证明不难. 对和的情况则要用到高等概率论, 这些都不在此细讲了.
要注意到定理 1.2 和 1.1 之间的区别: 后者不要求变量有独 立性. 读者也可以思考一下这个问题: 如果说, 事件积的概率的定 理 (第一章定理 3.3) 与此处定理 1.2 完全对应, 那么, 为什么事件 和概率的定理 (第一章定理 3.1) 与此处的定理 1.1 并不完全对应 (概率加法定理中有互斥要求而定理 1.1 无任何要求), 道理何在?
定理 1.3(随机变量函数的期望) 设随机变量 \(X\) 为离散型, 有分布 \(P\left(X=a_{i}\right)=p_{i}, i=1,2, \cdots\), 或者为连续型, 有概率密度函 数 \(f(x)\). 则
或
这个定理的实质在于: 为了计算 \(X\) 的某一函数 \(g(X)\) 的期望, 并不需要先算出 \(g(X)\) 的密度函数, 而可以就从 \(X\) 的分布出发, 这当然大大方便了计算, 因为在 \(g\) 较为复杂时, \(g(X)\) 的密度很难 求.
证 离散型情况 (1.17) 好证, 因为 \(P\left(X=a_{i}\right)=p_{i}\), 有 \(P(g\) \(\left.(X)=g\left(a_{i}\right)\right)=p_{i} \quad\left(g\left(a_{1}\right), g\left(a_{2}\right), \cdots\right.\) 中可以有相重的,但这并 不影响下面的证明). 由此立即得出(1.17).
连续型情况较复杂, 我们只能就 \(g\) 为严格上升并可导的情况 给出证明. 按第二章 (4.2) 式, 这时 \(Y=g(X)\) 的密度函数为 \(f(h\) \((y)) h^{\prime}(y)\), 其中 \(h\) 为 \(g\) 的反函数, 即 \(h(g(x))=x\). 此式两边对 \(x\) 求导, 得 \(\left.h^{\prime}(y)\right|_{y=g(x)} g^{\prime}(x)=1\), 即 \(h^{\prime}(g(x))=1 / g^{\prime}(x)\). 因此
作积分变数代换 \(y=g(x)\), 注意到 \(f(h(g(x)))=f(x), h^{\prime}(g\) \((x))=1 / g^{\prime}(x)\) 及 \(\mathrm{d} y=g^{\prime}(x) \mathrm{d} x\), 得
即 (1.18), 一般情况 ( \(g\) 非单调) 的证明超出本书范围之外, 但对有 些简单情况, \(g(X)\) 虽非单调, 但 \(g(X)\) 的密度不难求得, 这时 (1.18)也不难证. 有几种这样的情况作为习题留给读者.
本定理的一个重要特例是
系 1.1 若 \(c\) 为常数, 则
证明由取 \(g(x)=c x\) 得出. 当然, 直接证明也很容易.
这几个定理无论在理论上和实用上都有重大意义,这里我们 举几个例子说明其应用.
例 1.6 设 \(X\) 服从二项分布 \(B(n, p)\), 求 \(E(X)\).
此例不难由定义 1.1 直接计算, 但如下考虑更简单: 因 \(X\) 为 \(n\) 次独立试验中某事件 \(A\) 发生的次数, 且在每次试验中 \(A\) 发生的 概率为 \(p\). 故如引进随机变量 \(X_{1}, \cdots, X_{n}\), 其中
则 \(X_{1}, \cdots, X_{n}\) 独立, 且
按定理 1.1 有, \(E(X)=E\left(X_{1}\right)+\cdots+E\left(X_{n}\right)\). 为计算 \(E\left(X_{i}\right)\), 注 意按定义 \((1.20), X_{i}\) 只取两个值 1 和 0 , 其取 1 的概率为 \(p\), 取 0 的概率为 \(1-p\). 因而 \(E\left(X_{i}\right)=1 \times p+0 \times(1-p)=p\). 由此得到
这比直接计算要简单些, 又注意: 在上述论证中并末用到 \(X_{1}, \cdots\), \(X_{n}\) 独立这一事实.
例 1.7 再考虑第一章例 2.2 那个 “ \(n\) 双鞋随机地分成 \(n\) 堆” 的试验,以 \(X\) 记“恰好成一双”的那种堆的数目,求 \(E(X)\).
此题若要直接用定义 1.1 , 就须计算 \(P(X=i)\), 即“恰好有 \(i\) 个堆各自成一双”的概率.这个概率计算不易,但使用上例的方法 不难求解: 引进随机变量 \(X_{1}, \cdots, X_{n}\), 其中
则仍有 \(X=X_{1}+\cdots+X_{n}\), 且 \(E\left(X_{i}\right)=P\left(X_{i}=1\right)=P\) (第 \(i\) 堆恰成 一双). 为算这个概率, 我们取如下的分堆方法: 先把 \(2 n\) 只鞋随机 地自左至右排成一列, 然后让排在 1,2 位置的成一堆, 3,4 位置的 为第二堆,等等. 总的排列方法有 \((2 n)\) ! 种. 有利于事件 \(\{\) 第 \(i\) 堆 恰成一双 的排法可计算如下: 第 \(i\) 堆占据排列中的第 \((2 i-1)\) 和 第 \(2 i\) 号位置. 第 \((2 i-1)\) 号位置可以从 \(2 n\) 只鞋中任取一只, 有 \(2 n\) 种取法. 这只定了以后, 为使恰成一双, 第 \(2 i\) 号位置就只有一 种取法. 取好后, 剩下的 \(2 n-2\) 只则可任意排, 有 \((2 n-2)\) ! 种排 法. 因此, 有利于上述事件的总排列数为 \(2 n \cdot 1 \cdot(2 n-2)\) !, 而所求 的概率为
此即为 \(E\left(X_{i}\right)\), 而 \(E(X)=E\left(X_{1}\right)+\cdots+E\left(X_{n}\right)=n /(2 n-1)\)
例 1.8 试计算“统计三大分布”的期望值.
对自由度 \(n\) 的卡方分布,直接用其密度函数的形式 (第二章 (4.26)), \(\Gamma\) 函数的公式 (第二章 (4.23)) 及数学期望的定义 1.3 , 不难算出其期望为 \(n\). 略简单一些是用第二章例 4.9 , 把 \(X\) 表为 \(X_{1}^{2}+\cdots+X_{n}^{2}, X_{1}, \cdots, X_{n}\) 独立且各服从标准正态分布 \(N(0,1)\). 按 定理 1.3 ,有
把 \(\mathrm{e}^{-x^{2} / 2} x^{2} \mathrm{~d} x\) 写为 \(-x \mathrm{~d}\left(\mathrm{e}^{-x^{2} / 2}\right)\), 用分部积分, 得到
后一式用第二章 (1.15). 于是得到 \(E\left(X_{i}^{2}\right)=1\), 而 \(E(X)=E\left(X_{1}^{2}\right)\) \(+\cdots+E\left(X_{n}^{2}\right)=n\).
对自由度 \(n\) 的 \(t\) 分布, 由于其密度函数 (第二章 (4.31) 式) 关 于 0 对称, 易见其期望为 0 . 但是有一个条件, 就是自由度 \(n\) 必须 大于 1 . 这是因为
因而条件(1.4)不适合,当 \(n>1\) 时上式的积分有限.
对自由度为 \(m, n\) 的 \(F\) 分布, 写
其中 \(X_{1}, X_{2}\) 独立, 分别服从分布 \(\chi_{n}^{2}\) 和 \(\chi_{m}^{2}\). 由于 \(X_{1}, X_{2}\) 独立, 按 第二章定理 3.3 , 知 \(X_{1}^{-1}\) 和 \(X_{2}\) 也独立, 故按定理 1.2 , 有
于是问题归结为计算 \(E\left(X_{1}^{-1}\right)\). 按定理 1.3 , 有
由此及 \((1.23)\), 知
此式只在 \(n>2\) 时才有效. 当 \(n=1,2\) 时, \(F_{m, n}\) 的期望不存在.
1.3. 3 条件数学期望(条件均值)⚓︎
与条件分布的定义相似,随机变量 \(Y\) 的条件数学期望,就是 它在给定的某种附加条件之下的数学期望. 对统计学来说, 最重要 的情况是: 在给定了某些其他随机变量 \(X, Z, \cdots\) 等的值 \(x, z, \cdots\) 等 的条件之下, \(Y\) 的条件期望, 记为 \(E(Y \mid X=x, Z=z, \cdots)\). 以只有 一个变量 \(X\) 为例, 就是 \(E(Y \mid X=x)\). 在 \(X\) 已明确而不致引起误 解的情况下, 也可简记为 \(E(Y \mid x)\).
如果知道了 \((X, Y)\) 的联合密度,则 \(E\left(\left.Y\right|_{x}\right)\) 的定义就可以具 体化为: 先定出在给定 \(X=x\) 之下, \(Y\) 的条件密度函数 \(f(y \mid x)\), 然后按定义 1.3 算出
如果说, 条件分布是变量 \(X\) 与 \(Y\) 的相依关系在概率上的完全 刻画,那么, 条件期望则在一个很重要的方面刻画了二者的关系, 它反映了随着 \(X\) 取值 \(x\) 的变化, \(Y\) 的平均变化的情况如何, 而这 常常是研究者所关心的主要内容.例如,随着人的身高 \(x\) 的变化, 具身高 \(x\) 的那些人的平均体重的变化情况如何; 随着其受教育年 数 \(x\) 的变化,其平均收人的变化如何等等. 在统计学上,常把条件 期望 \(E(Y \mid x)\) 作为 \(x\) 的函数称为 \(Y\) 对 \(X\) 的 “回归函数” (回归这 个名词将在第六章中解释), 而 “回归分析”, 即关于回归函数的统 计研究,构成统计学的一个重要分支.
例 1.9 条件期望的一个最重要的例子是 \((X, Y)\) 服从二维正 态分布 \(N\left(a, b, \sigma_{1}^{2}, \sigma_{1}^{2}, \rho\right)\). 根据第二章例 3.3, 在给定 \(X=x\) 时 \(Y\) 的条件分布为正态分布 \(N\left(b+\rho \sigma_{2} \sigma_{1}^{-1}(x-a), \sigma_{2}^{2}\left(1-\rho^{2}\right)\right)\). 因为 正态分布 \(N\left(\mu, \sigma^{2}\right)\) 的期望就是 \(\mu\),故有
它是 \(x\) 的线性函数. 如果 \(\rho>0\), 则 \(E(Y \mid x)\) 随 \(x\) 增加而增加, 即 \(Y\) “平均说来”有随 \(X\) 的增长而增长的趋势, 这就是我们以前提到 的“正相关”的解释. 若 \(\rho<0\), 则为负相关, 当 \(\rho=0\) 时, \(X\) 与 \(Y\) 独 立, \(E(Y \mid x)\) 当然与 \(x\) 无关.
从条件数学期望的概念, 可得出求通常的 (无条件的) 数学期 望的一个重要公式. 这个公式与计算概率的全概率公式相当. 回想 全概率公式 \(P(A)=\sum_{i} P\left(B_{i}\right) P\left(A \mid B_{i}\right)\). 它可以理解为通过事 件 \(A\) 的条件概率 \(P\left(A \mid B_{i}\right)\) 去计算其 (无条件) 概率 \(P(A)\). 更确定 地说, \(P(A)\) 就是条件概率 \(P\left(A \mid B_{i}\right)\) 的某种加权平均, 权即为事件 \(B_{i}\) 的概率. 以此类推,变量 \(Y\) 的 (无条件)期望,应等于其条件期 望 \(E(Y \mid x)\) 对 \(x\) 取加权平均, \(x\) 的权与变量 \(X\) 在 \(x\) 点的概率密度 \(f_{1}(x)\) 成比例, 即
此式很容易证明: 以 \(f(x, y)\) 记 \((X, Y)\) 的联合密度函数, 则 \(X, Y\) 的 (边缘) 密度函数分别为
按定义, \(E(Y)=\int_{-\infty}^{\infty} y f_{2}(y) \mathrm{d} y\), 可写为
由于 \(E(Y \mid x)=\int_{-\infty}^{\infty} y f(x, y) \mathrm{d} y / f_{1}(x)\), 有 \(\int_{-\infty}^{\infty} y f(x, y) \mathrm{d} y=\) \(E(Y \mid x) f_{1}(x)\), 而上式转化为 \((1.27)\).
公式 (1.27) 可给以另一种写法, 记 \(g(x)=E(Y \mid x)\), 它是 \(x\) 的函数, 则 \((1.27)\) 成为
但据 (1.18), 上式右边就是 \(E(g(X))\). 从 \(g(x)\) 的定义, \(g(X)\) 是 \(\left.E(Y \mid x)\right|_{x=X}\), 可简写为 \(E(Y \mid X)\). 于是由 \((1.28)\) 得
这个公式可以形象地叙述为:一个变量 \(Y\) 的期望, 等于其条件期 望的期望. \(E(Y \mid X)\) 这个符号的意义,从上面的叙述中已明确交代 了, 只须记住: 在求 \(E(Y \mid X)\) 时, 先设定 \(X\) 等于一固定值 \(x, x\) 无 随机性, 这样可算出 \(E(Y \mid x)\), 其表达式含 \(x\), 再把 \(x\) 换成 \(X\) 即 得.
公式 (1.29) 虽可算是概率论中一个比较高深的公式, 它的实 际含义其实很简单: 它可理解为一个 “分两步走”去计算期望的方 法. 因为在不少情况下, 迳直计算 \(E(Y)\) 较难, 而在限定某变量 \(X\) 之值后, 计算条件期望 \(E(Y \mid x)\) 则较容易. 因此我们分两步走:第 一步算出 \(E(Y \mid x)\), 再借助 \(X\) 的概率分布, 通过 \(E(Y \mid x)\) 算出 \(E(Y)\). 更直观一些, 你可以把求 \(E(Y)\) 看成为在一个很大的范围 求平均. 限定 \(X\) 之值从这个很大的范围内界定了一个较小的部 分. 先对这较小的部分求平均,然后再对后者求平均. 比如要求全 校学生的平均身高, 你可以先求出每个班的学生的平均身高, 然后 再对各班的平均值求一次平均. 自然, 在作后一平均时, 要考虑到 各班人数的不同, 是以各班人数为权的加权平均. 这个权的作用相 当于公式 (1.27) 中的 \(f_{1}(x)\).
公式 (1.29) 虽来自 (1.27), 但因为其形式并不要求对 \(X, Y\) 有特殊的假设, 故可适用于更为一般的情形. 例如, \(X\) 不必是一维 的, 如果 \(X\) 为 \(n\) 维随机向量 \(\left(X_{1}, \cdots, X_{n}\right)\), 有概率密度 \(f\left(x_{1}, \cdots\right.\), \(\left.x_{n}\right)\), 则公式 (1.29) 有形式
这里 \(E\left(Y \mid x_{1}, \cdots, x_{n}\right)\) 就是在 \(X_{1}=x_{1}, \cdots, X_{n}=x_{n}\) 的条件下, \(Y\) 的条件期望, 又 \(X, Y\) 都可以是离散型的. 例如, 设 \(X\) 为一维离散 型变量, 有分布
则公式 (1.29)有形式
1.4. 4 中位数⚓︎
刻画一个随机变量 \(X\) 的平均取值的数学特征, 除了数学期望 以外,最重要的是中位数.
定义 1.4 设连续型随机变量 \(X\) 的分布函数为 \(F(x)\), 则满 足条件
的数 \(m\) 称为 \(X\) 或分布 \(F\) 的中位数.
由于连续型变量取一个值的概率为 \(0, P(X=m)=0\), 由 \((1.32)\) 知
就是说, \(m\) 这个点把 \(X\) 的分布从概率上一切两半: 在 \(m\) 左边(包 括点 \(m\) 与否无所谓) 占一半, \(m\) 右边也占一半, 从概率上说, \(m\) 这 个点正好居于中央, 这就是“中位数” 得名的由来.
在实用上, 中位数用得很多, 特别有不少社会统计资料, 常拿 中位数来刻画某种量的代表性数值, 有时它比数学期望更说明问 题. 例如, 某社区内人的收人的中位数告诉我们: 有一半的人收人 低于此值, 另一半高于此值. 我们直观上感觉到这个值对该社区的 收入情况, 的确很具代表性. 它和期望值相比它的一个优点是: 它 受个别特大或特小值的影响很小, 而期望则不然. 举例而言, 若该 社区中有一人收人在百万元以上, 则该社区的均值可能很高, 而绝 大多数人并不富裕, 这个均值并不很有代表性. 中位数则不然: 它 不受少量这种特大值的影响.
从理论上说, 中位数与均值相比还有一个优点, 即它总存在, 而均值则不是对任何随机变量都存在.
虽则中位数有这些优点, 但在概率统计中, 无论在理论和应用 上, 数学期望的重要性都超过中位数, 其原因有以下两方面:
一是均值具有很多优良的性质, 反映在前面的定理 1.11.3. 这些性质使得在数学上处理均值很方便. 例如, \(E\left(X_{1}+X_{2}\right)\) \(=E\left(X_{1}\right)+E\left(X_{2}\right)\), 这公式既简单又毫无条件(除了均值存在以 外). 中位数则不然: \(X_{1}+X_{2}\) 的中位数, 与 \(X_{1}, X_{2}\) 各自的中位数 之间, 不存在简单的联系, 这使中位数在数学上的处理很复杂且不 方便。
二是中位数本身所固有的某些缺点. 首先, 中位数可以不唯 一. 例如, 考察图 3.2 的密度函数 \(f\). 它只在两个分开的区间 \((a\), \(b)\) 和 \((c, d)\) 内不为 0 , 且在这两段区间上围成的面积都是 \(1 / 2\). 这 时, 按中位数的定义 1.4 , 区间 \([b, c]\) 中任何一点 \(m\) 都是中位数. 它没有一个唯一的值.
次一个问题是: 在 \(X\) 为离散型的情况, 虽也可以定义中位数 (其定义与定义 1.4 有所不同),但并不很理想,不完全符合“中位” 这名词所应有的含义. 考察一个简单例子, 设 \(X\) 取三个值 \(1,2,3\), 概率分布为
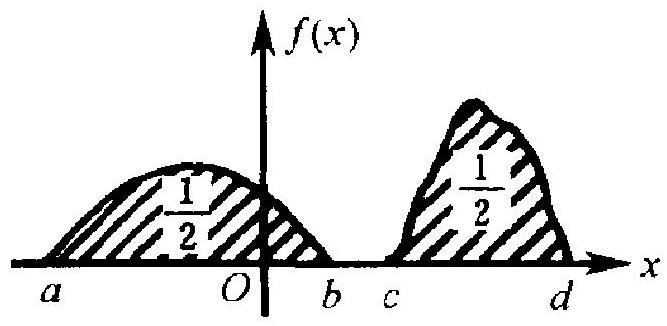
图 3.2
这时就不存在一个点 \(m\), 使 \(m\) 两边的概率恰好一样, 不得已只好 退而求其次: 找一个点 \(m\), 使其左右两边的概率差距最小, 在本例 中这个点是 2 . 从 2 这个位置看, 左边的概率 \((2 / 7)\) 要比右边的概 率 \((1 / 7)\) 大. 故并不是理想的“中位”数.
例 1.10 正态分布 \(N\left(\mu, \sigma^{2}\right)\) 的中位数就是 \(\mu\), 这从 \(N(\mu\), \(\left.\sigma^{2}\right)\) 的密度函数关于 \(\mu\) 点对称可以看出. 指数分布函数已在第二 章 (1.21) 式中列出, 故其中位数 \(m\) 为方程 \(1-\mathrm{e}^{-\lambda m}=1 / 2\) 的解, 即 \(m=(\log 2) / \lambda(\) 本书中, \(\log\) 都是以 \(\mathrm{e}\) 为底).
评论
登录github的账号后,可以直接在下方评论框中输入。
如果想进行更详细的讨论(如排版、上传图片等),选择一个反应后并点击上方的文字,进入论坛页面。