4.4 区间估计⚓︎
4.4 区间估计⚓︎
0.1. 1 基本概念⚓︎
如前所述, 点估计是用一个点 (即一个数) 去估计末知参数. 顾 名思义, 区间估计就是用一个区间去估计末知参数, 即把末知参数 值估计在某两界限之间. 例如, 估计一个人的年龄在 30 到 35 岁之 间; 估计所需费用在 \(1000-1200\) 元之间等等. 区间估计是一种很 常用的估计形式,其好处是把可能的误差用醒目的形式标出来了. 你估计费用需 1000 元, 我相信多少会有误差. 误差多少? 单从你 提出的 1000 这个数字还给不出什么信息, 你若估计费用在 800 1200 元之间,则人们会相信你在作出这估计时, 已把可能出现的 误差考虑到了,多少给人们以更大的信任感. 现今最流行的一种区间估计理论是原籍波兰的美国统计学家 \(\mathrm{J}\). 奈曼在本世纪 30 年代建立起来的. 他的理论的基本概念很简 单. 为书写简单计, 我们暂设总体分布只包含一个末知参数 \(\theta\), 且 要估计的就是 \(\theta\) 本身.如果总体分布包含若干个末知参数 \(\theta_{1}, \cdots\), \(\theta_{k}\), 而要估计的是 \(g\left(\theta_{1}, \cdots, \theta_{k}\right)\), 基本概念并无不同. 这将在后面 的例子中看到。
设 \(X_{1}, \cdots, X_{n}\) 是从该总体中抽出的样本. 所谓 \(\theta\) 的区间估计, 就是满足条件 \(\hat{\theta}_{1}\left(X_{1}, \cdots, X_{n}\right) \leqslant \hat{\theta}_{2}\left(X_{1}, \cdots, X_{n}\right)\) 的两个统计量 \(\hat{\theta}_{1}\), \(\hat{\theta}_{2}\) 为端点的区间 \(\left[\hat{\theta}_{1}, \hat{\theta}_{2}\right]\). 一旦有了样本 \(X_{1}, \cdots, X_{n}\), 就把 \(\theta\) 估计 在区间 \(\left[\hat{\theta}_{1}\left(X_{1}, \cdots, X_{n}\right), \hat{\theta}_{2}\left(X_{1}, \cdots, X_{n}\right)\right]\) 之内, 不难理解, 这里有 两个要求:
- \(\theta\) 要以很大的可能性落在区间 \(\left[\hat{\theta}_{1}, \hat{\theta}_{2}\right]\) 内, 也就是说, 概率
要尽可能大.
- 估计的精密度要尽可能高. 比方说, 要求区间的长度 \(\hat{\theta}_{2}-\) \(\hat{\theta}_{1}\) 尽可能小, 或某种能体现这个要求的其他准则.
例如,估一个人的年龄在某一区间内,例如 \([30,35]\) 内. 我们要 求这估计尽量可靠, 即该人的年龄有很大把握确在这区间内, 同 时, 也要求区间不能太长: 比如, 估计一人的年龄在 10-90 岁之 间, 当然可靠了,但精度太差,用处不大.
但这两个要求是相互矛盾的. 区间估计理论和方法的基本问 题, 莫不在于在已有的样本资源的限制下,怎样找出更好的估计方 法, 以尽量提高此二者一一可靠性和精度, 但终归有一定的限度. 奈曼所提出并为现今所广泛接受的原则是: 先保证可靠度,在这个 前提下尽量使精度提高. 为此他引进了如下的定义.
定义 4.1 给定一个很小的数 \(\alpha>0\). 如果对参数 \(\theta\) 的任何 值, 概率 \((4.1)\) 都等于 \(1-\alpha\), 则称区间估计 \(\left[\hat{\theta}_{1}, \hat{\theta}_{2}\right]\) 的置信系数为 \(1-\alpha\).
区间估计也常称为“置信区间”, 字面上的意思是: 对该区间能 包含末知参数 \(\theta\) 可置信到何种程度.
有时, 我们无法证明概率 (4.1) 对一切 \(\theta\) 都恰好等于 \(1-\alpha\), 但 知道它不会小于 \(1-\alpha\),则我们称 \(1-\alpha\) 是 \(\left[\hat{\theta}_{1}, \hat{\theta}_{2}\right]\) 的 “置信水平”. 按此, 置信水平不是一个唯一的数. 因为, 若概率 (4.1) 总不小于 0.8 , 那它也总不小于 \(0.7,0.6\), \(\cdots\) 等. 就是说, 若 \(\beta\) 为置信水平, 则 小于 \(\beta\) 的数也是置信水平, 置信系数是置信水平中的最大者. 在 实用上, 人们并不总是把这两个术语严加区别, 这要看各人的习 惯.
定义 4.1 中的 \(\alpha\),一般以取为 0.05 的最多,还有 \(0.01,0.10\), 以至 0.001 等,也视情况需要而使用. 这几个数字本身并无特殊意 义, 主要是这样标准化了以后对造表方便.
区间估计理论的主要问题,按奈曼的上述原则, 就是在保证给 定的置信系数之下, 去寻找有优良精度的区间估计.而这个“优 良”, 也可以有种种准则. 这方面现已有了一些结果, 但在本课程范 围之内, 我们无法去涉及这些较深的理论问题,我们所能做的, 就 是从直观出发如何去构造看来是合理的区间估计. 这就是下面两 段要讨论的问题.
0.2. 2 枢轴变量法⚓︎
从一个简单例子人手. 设 \(X_{1}, \cdots, X_{n}\) 为抽自正态总体 \(N(\mu\), \(\left.\sigma^{2}\right)\) 的样本, \(\sigma^{2}\) 已知, 要求 \(\mu\) 的区间估计.
先找一个 \(\mu\) 的良好的点估计. 在此可选择样本均值 \(\bar{X}\). 由总 体为正态易知
以 \(\Phi\) 记 \(N(0,1)\) 的分布函数. 对 \(0<\beta<1\) (一般是 \(\beta\) 很小), 用方程
定义记号 \(u_{\beta} \cdot u_{\beta}\) 称为分布 \(N(0,1)\) 的 “上 \(\beta\) 分位点”. 其意义是: \(N(0,1)\) 分布中大于 \(u_{\beta}\) 的那部分的概率, 就是 \(\beta\). 图 4.2 中画出的 是 \(N(0,1)\) 的密度函数 \(\varphi(x)=(\sqrt{2 \pi})^{-1} \mathrm{e}^{-x^{2} / 2}\) 的图形, 涂黑部分 标出的面积为 \(\beta\).
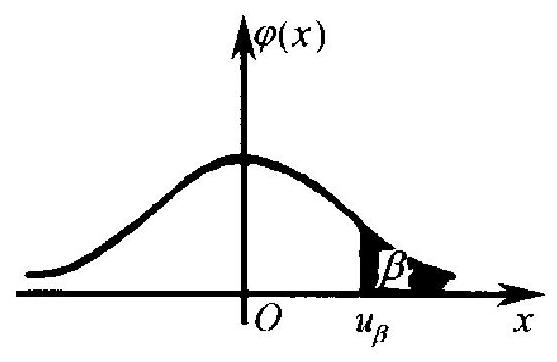
图 4.2
上 \(\beta\) 分位点的概念可推广到任 何分布 \(F\) : 满足条件 \(F\left(v_{\beta}\right)=1-\beta\) 的 点 \(v_{\beta}\), 就是分布函数 \(F\) 的上 \(\beta\) 分位 点. 在数理统计学的应用中, 除正态 分布外,“统计三大分布”的上分位点 很常用. 以后, 我们分别用 \(x_{n}^{2}(\beta), t_{n}\) \((\beta)\) 和 \(F_{n, m}(\beta)\) 记自由度 \(n\) 的卡方 分布, 自由度 \(n\) 的 \(t\) 分布, 以及自由 度为 \((n, m)\) 的 \(F\) 分布的上 \(\beta\) 分位点,这些都有表可查.
另外,读者还须注意: 在有的著作中使用“下分位点”,分布函 数 \(F\) 的下 \(\beta\) 分位点是指满足条件 \(F\left(w_{\beta}\right)=\beta\) 的点 \(w_{\beta}\). 上、下分位 点之间的换算不难: 分布 \(F\) 的 \(\beta\) 下分位点, 就是其 \(1-\beta\) 上分位 点. 当分布 \(F\) 的密度函数 \(f\) 关于原点对称 (即 \(f(-x)=f(x)\) ) 时, \(F\) 的上、下 \(\beta\) 分位点只相差一个符号, 本书以后只使用上分位点.
现在回到 \(\mu\) 的区间估计问题. 由 (4.2) 及 \(\mu_{\beta}\) 的定义, 并注意 到 \(\Phi(-t)=1-\Phi(t)\), 有
此式可改写为
此式指出
可作为 \(\mu\) 的区间估计,置信系数为 \(1-\alpha\).
由这个例子悟出一种找区间估计的一般方法, 可总结为以下 几条 :
\(1^{\circ}\) 找一个与要估计的参数 \(g(\theta)\) 有关的统计量 \(T\), 一般是其
1. 一良好的点估计 (此例 \(T\) 为 \(\bar{X}\) );⚓︎
\(2^{\circ}\) 设法找出 \(T\) 和 \(g(\theta)\) 的某一函数 \(S(T, g(\theta))\), 其分布 \(F\) 要与 \(\theta\) 无关 (在此例中, \(S(T, g(\theta))\) 为 \(\sqrt{n}(\bar{X}-\mu) / \sigma\), 分布 \(F\) 就 是 \(\Phi)\). \(S\) 称为“枢轴变量”;
\(3^{\circ}\) 对任何常数 \(a<b\), 不等式 \(a \leqslant S(T, g(\theta)) \leqslant b\) 要能改写 为等价的形式 \(A \leqslant g(\theta) \leqslant B, A, B\) 只与 \(T, a, b\) 有关而与 \(\theta\) 无关;
\(4^{\circ}\) 取分布 \(F\) 的上 \(\alpha / 2\) 分位点 \(w_{\alpha / 2}\) 和上 \((1-\alpha / 2)\) 分位点 \(w_{1-\alpha / 2}\). 有 \(F\left(w_{\alpha / 2}\right)-F\left(w_{1-\alpha / 2}\right)=1-\alpha\). 因此
根据第 3 条, 不等式 \(w_{1-\alpha / 2} \leqslant S(T, g(\theta)) \leqslant w_{\alpha / 2}\) 可改写为 \(A \leqslant\) \(g(\theta) \leqslant B\) 的形式, \(A, B\) 与 \(T\) 有关因而与样本有关. \([A, B]\) 就是 \(g\) \((\theta)\) 的一个置信系数 \(1-\alpha\) 的区间估计.
现在举一些例子来说明这个方法,这些例子包含了许多常用 的重要区间估计.
例 4.1 从正态总体 \(N\left(\mu, \sigma^{2}\right)\) 中抽样本 \(X_{1}, \cdots, X_{n}, \mu\) 和 \(\sigma^{2}\) 都末知,求 \(\mu\) 的区间估计.
\(\mu\) 的点估计仍取为样本均值 \(\bar{X}\). 作为枢轴变量, 再取 \(\sqrt{n}(\bar{X}-\) \(\mu) / \sigma\) 已不行. 因为虽然这变量的分布 \(N(0,1)\) 与参数无关, 但因 \(\sigma\) 末知, 条件 \(3^{\circ}\) 已不满足. 现把 \(\sigma\) 改为样本标准差 \(S\), 则枢轴变量一 切条件都满足了, 因为 (见第二章 (4.34)) 变量 \(\sqrt{n}(\bar{X}-\mu) / S\) 服 从自由度为 \(n-1\) 的 \(t\) 分布, 与参数无关. 由此出发用 \(4^{\circ}\), 并注意 \(t\) 分布密度关于 0 对称因而 \(t_{n-1}(1-\alpha / 2)=-t_{n-1}(\alpha / 2)\), 得 \(\mu\) 的 区间估计
置信系数为 \(1-\alpha\). 它称为“一样本 \(t\) 区间估计”.
例如,为估计一物件的重量 \(\mu\), 把它在天平上重复秤了 5 次, 得结果为 (单位为克)
假定此天平无系统误差且随机误差服从正态分布. 则总体分布为 \(N\left(\mu, \sigma^{2}\right), \mu\) 即末知的重量, 方差 \(\sigma^{2}\) 也末知. 算出
查表, 知 \(t_{4}(0.025)=2.776\). 以这些数值代人 (4.5), 得 \(\mu\) 的置信 系数 0.95 的区间估计为 \([5.419,5.613]\).
\([5.419,5.613]\) 是一个具体的区间, \(\mu\) 是一个虽然末知, 但其 值确定的数. \([5.419,5.613]\) 这区间或者包含 \(\mu\), 或者不包含, 二者 只居其一. 说这区间的置信系数为 0.95 , 其确切意义应当是: 它是 根据所有的数据, 用一个其置信系数为 0.95 的方法作出的. 可见 置信系数一词是针对方法: 用这方法作出的区间估计,平均 100 次 中 95 次确包含所要估计的值. 一旦算出具体区间, 就不能再说它 有 \(95 \%\) 的机会包含要估计的值了. 这一点意义上的理解必须分 清, 正如说一个人长于挑西瓜: 他挑的瓜, 平均 100 个中有 95 个好 的. 某天他给你挑一个,结果或好或坏,必居其一, 不是 \(95 \%\) 的好. 但是, 考虑到他挑瓜的技术, 我对他挑的比较放心, 这就是置信系 数.
区间估计 (4.5) 叫做一样本 \(t\) 区间估计. “一样本”是指这里只 有一个总体, 因而只有一组样本, 以别于下例.
例 4.2 设有两个正态总体, 其分布分别为 \(N\left(\mu_{1}, \sigma^{2}\right)\) 和 \(N\left(\mu_{2}, \sigma^{2}\right)\). 注意方差相同. 设 \(\mu_{1}, \mu_{2}, \sigma^{2}\) 都末知. 现从这两个总体 分别抽出样本 \(X_{1}, \cdots, X_{n}\) 和 \(Y_{1}, \cdots, Y_{m}\). 要求 \(\mu_{1}-\mu_{2}\) 的区间估 计.
记 \(\bar{X}\) 和 \(\bar{Y}\) 分别为 \(X_{i}\) 和 \(Y_{j}\) 的样本均值, 而
据第二章 \((4.36)\) 式,知
的分布不依赖于参数 \(\mu_{1}, \mu_{2}, \sigma^{2}\). 它适合于作为枢轴变量的条件, 按 \(4^{\circ}\), 定出 \(\mu_{1}-\mu_{2}\) 的区间估计为
置信系数为 \(1-\alpha\). 这个区间称为 “两样本 \(t\) 区间估计”, 是应用上 常用的区间估计之一。
如考虑上例, 设有另一物件, 其重量 \(\mu_{2}\) 也末知. 在这国一架 天平上科 4 次, 得结果为
把上例中的 \(\mu\) 记为 \(\mu_{1}\). 因是同一架天平, 方差不变. 要对两物件重 量之差 \(\mu_{1}-\mu_{2}\) 作区间估计. 可用(4.6). 算出
结合前例数据,算出
又 \(\sqrt{(n+m) / n m}=\sqrt{9 / 20}=0.671\). 取 \(\alpha=0.05\), 查 \(t\) 分布表得 \(t_{7}(0.025)=2.365\). 把这些都代入 (4.6), 算出 \(\mu_{1}-\mu_{2}\) 的区间估计 为 \([-0.210,0.028]\), 置信系数 0.95 .
在实际问题中,两总体方差相等的假定往往只是近似成立. 当 方差之比接近 1 时,用(4.6) 产生的误差不大(这里的“误差”一词 是指实际的置信系数与名义的置信系数 \(1-\alpha\) 有出入). 如果差别 较大, 则必须假定两正态总体分别有方差 \(\sigma_{1}^{2}\) 和 \(\sigma_{2}^{2}, \sigma_{1}^{2}\) 和 \(\sigma_{2}^{2}\) 都末 知. 在这样的假定下求 \(\mu_{1}-\mu_{2}\) 的区间估计问题, 是数理统计学上 一个著名的问题,叫贝伦斯一费歇尔问题. 因为这两位学者分别在 1929 和 1930 年研究过这个问题, 他们以及后来的研究者提出过 一些解法, 但还没有一个被公认为是最满意的.
例 4.3 再考虑例 4.1 , 但现在要求作 \(\sigma^{2}\) 的区间估计.
据第二章 \((4.33)\), 有 \((n-1) S^{2} / \sigma^{2}-\chi_{n-1}^{2}\). 于是 \((n-1) S^{2} / \sigma^{2}\) 适合枢轴变量的条件. 按 \(4^{\circ}\), 得 \(\sigma^{2}\) 的区间估计为
置信系数为 \(1-\alpha\). 类似地, 若另有一正态总体 \(N\left(\mu, \sigma_{2}^{2}\right)\) 及从中抽 出的样本 \(Y_{1}, \cdots, Y_{m}\), 要作方差比 \(\sigma_{1}^{2} / \sigma_{2}^{2}\) 的区间估计. 记 \(S_{1}^{2}\) 和 \(S_{2}^{2}\) 分别为 \(X_{1}, \cdots, X_{n}\) 和 \(Y_{1}, \cdots, Y_{m}\) 的样本方差, 按第二章 (4.35), 有
即 \(\lambda \cdot S_{2}^{2} / S_{1}^{2} \sim F_{m-1, n-1}\), 其中 \(\lambda=\sigma_{1}^{2} / \sigma_{2}^{2}\). 于是得到枢轴变量. 按 \(4^{\circ}\), 得出比值 \(\lambda\) 的置信系数 \(1-\alpha\) 的区间估计为
例 4.4 设 \(X_{1}, \cdots, X_{n}\) 为抽自指数分布总体的样本, 要求其 参数 \(\lambda\) 的区间估计.
在第二章 2.4 .3 小节中曾证明 \(2 n \lambda \bar{X} \sim \chi^{2} 2 n\). 故 \(2 n \lambda \bar{X}\) 可作为 枢轴变量. 由 \(4^{\circ}\),得 \(\lambda\) 的区间估计为
置信系数为 \(1-\alpha\). 若要求总体均值 \(1 / \lambda\) 的区间估计, 则为
从这些例子可以看出“枢轴变量法”这名称的由来.拿本例来 说, 变量 \(2 n \lambda \bar{X}\) 起了一个“轴心”的作用, 把一个变量 (即 \(2 n \lambda \bar{X})\) 介 于某两个界限之间的不等式轻轻一转, 就成为末知参数 \(\lambda\) 介于某 两个界限之间的不等式.
对离散型变量来说, 枢轴变量法不易使用. 不仅由于满足条件 \(1^{\circ}-4^{\circ}\) 的枢轴变量 \(S(T, g(\theta))\) 大多不存在, 即使存在了, 由于其 分布 \(F\) 为离散, 对指定的 \(\beta\),一般也不一定存在确切的上 \(\beta\) 分位 点. 对离散型总体的参数去找具有所指定的置信系数的区间估计 方法, 超出本书范围之外. 在下一段中, 对二项和波哇松分布参数 这两个重要情况, 将给出一种基于极限分布的方法.
在实用中, 除了指定的置信系数外, 往往还对于区间估计的长 度, 或其他某种反映其精度的量, 有一定的要求. 在有些情况下这 个问题比较好处理. 例如, \(N\left(\mu, \sigma^{2}\right)\) 当 \(\sigma^{2}\) 已知时, \(\mu\) 的区间估计 (4.4) 的长为 \(2 \sigma u_{\alpha / 2} / \sqrt{n}\). 为要使这个长度不超过指定的 \(L>0\), 只 须取 \(n\) 为不小于 \(\left(2 \sigma u_{\alpha / 2} / L\right)^{2}\) 的最小整数即可.
对例 4.3 正态分布方差或方差比的估计, 由于方差本身的意 义, 在实际问题中, 考虑估计值与它相差多少倍, 往往比考虑估计 值与其差的绝对值更好. 这就要求, 例如, 区间(4.7)的右端不超过 左端的 \(L\) 倍 \((L>1)\), 即
在给定了 \(L\) 之后, 可以查 \(\chi^{2}\) 分布表,找一个最小的 \(n\) 使上式成立 即可,对方差比的情况,以及指数分布参数 \(\lambda\) (或 \(1 / \lambda\) ) 的情况,也 完全类似地处理.
对 \(t\) 区间估计, 则情况不同,拿一样本 \(t\) 区间估计 (4.5) 来说, 其长 \(2 S t_{n-1}(\alpha / 2) / \sqrt{n}\) 与 \(S\) 有关, 而 \(S\) 与样本有关, 故无法决定这 样一个 \(n\), 它能保证在任何情况下都有 \(2 S t_{n-1}(\alpha / 2) / \sqrt{n} \leqslant L\). 1945 年, 美国统计学家斯泰因提出了一个“两阶段抽样”的方法来 解决这个问题: 先抽出样本 \(X_{1}, \cdots, X_{n}\), 算出样本标准差 \(S\) 如前. 根据 \(S\) 的大小决定追加抽样的数目: \(S\) 愈大,追加抽样次数愈多. 具体公式如下: 先引进记号 \([\alpha]=\) 不超过 \(\alpha\) 的最大整数, 例如 \([3.12]=3\), [2] \(=2\) 等, 追加抽样次数 \(m\) 的公式为
记原有样本和追加样本全体的样本均值为 \(\widetilde{X}\), 则可以证明, 长为 \(L\) 的区间估计 \([\tilde{X}-L / 2, \tilde{X}+L / 2]\) 有置信系数 \(1-\alpha\).
1.1. 3 大样本法⚓︎
大样本法就是利用极限分布, 主要是中心极限定理, 以建立枢 轴变量, 它近似满足枢轴变量的条件 \(2^{\circ}\). 最好通过例子来说明.
例 4.5 某事件 \(A\) 在每次试验中发生的概率为 \(p\). 作 \(n\) 次独 立试验, 以 \(Y_{n}\) 记 \(A\) 发生的次数,要求 \(p\) 的区间估计.
设 \(n\) 相当大, 则按定理 4.3 ,近似地有 \(\left(Y_{n}-n p\right) / \sqrt{n p(1-p)}\) \(\sim N(0,1)\). 于是 \(\left(Y_{n}-n p\right) / \sqrt{n p(1-p)} \sim N(0,1)\) 可取为枢轴变 量. 由
可政写为
其中 \(A, B\) 是二次方程
的两个根, 即
\(A\) 取负号, \(B\) 取正号, \(\hat{p}=Y_{n} / n\).
因为 (4.11) 和 (4.12) 只是近似的, 故区间估计 \([A, B]\) 的置信 系数,也只是近似地等于 \(1-\alpha\). 当 \(n\) 较大,例如 \(n \geqslant 30\) 时,相去不 远, 实际上, \(n\) 太小时, 找 \(p\) 的区间估计意义不大. 因为这种区间 都失之过长, 实际意义不大. 这可由下面的分析看出: 由于 \(0 \leqslant \hat{p} \leqslant\) \(1, \hat{p}(1-\hat{p})\) 的最大值可为 \(1 / 4\). 这时, 区间 \([A, B]\) 之长, 在把 \(\hat{p}(1\) \(-\hat{p}\) )改为 \(1 / 4\) 后, 为 \(u_{\alpha / 2} / \sqrt{n+u_{\alpha / 2}^{2}}\). 取 \(\alpha=0.05\), 有 \(u_{\alpha / 2}=1.96\). 若要求这区间之长不超过 0.3 (这是一个很低的要求), 必须 \(1.96 /\) \(\sqrt{n+(1.96)^{2}} \leqslant 0.3\). 算出 \(n\) 至少应为 39. 可以看出: 在试验次数 \(n\) 低于 40 时,求 \(p\) 的区间估计没有多大实用意义.
例 4.6 设 \(X_{1}, \cdots, X_{n}\) 为抽自有波哇松分布 \(P(\lambda)\) 的总体的 样本, 求 \(\lambda\) 的区间估计. 记 \(Y_{n}=X_{1}+\cdots+X_{n}\). 设 \(n\) 相当大, 注意到波哇松分布的均 伹方差都是 \(\lambda\), 由第三章定理 4.2 , 知 \(\left(Y_{n}-n \lambda\right) / \sqrt{n \lambda}\) 近似地有分 布 \(N(0,1)\). 仿前例的做法, 即得到 \(\lambda\) 的区间估计 \([A, B], A, B\) 为 次方程
的两根, 即
\(A\) 取负号, \(B\) 取正号, \(\bar{X}=Y_{n} / n\).
例 4.7 设某总体有均值 \(\theta\), 方差 \(\sigma^{2} . \theta\) 和 \(\sigma^{2}\) 都末知, 从这总 体中抽出样本 \(X_{1}, \cdots, X_{n}\), 要作 \(\theta\) 的区间估计.
因为对总体分布没有作任何假定, 要作出满足条件 \(1^{\circ}-4^{\circ}\) 的 枢轴变量是不可能的. 但是, 若 \(n\) 相当大,则据中心极限定理 (第 三章定理 4.2), 有 \(\sqrt{n}(\bar{X}-\theta) / \sigma \sim N(0,1)\). 但此处 \(\sigma\) 末知, 仍不 能以 \(\sqrt{n}(\bar{X}-\theta) / \sigma\) 作为枢轴变量. 因为 \(n\) 相当大, 样本均方差 \(S\) 是 \(\sigma\) 的一个相合估计, 故可近似地用 \(S\) 代 \(\sigma\), 得
由此就不难得出 \(\theta\) 的区间估计
它的置信系数, 当 \(n\) 相当大时, 近似地为 \(1-\alpha\). 近似的程度如何不 仅取决于 \(n\) 的大小,还要看总体的分布如何.
例 4.8 考虑在例 4.2 中提出的贝伦斯一费歇尔问题: \(X_{1}\), \(\cdots, X_{n}\) 是从正态总体 \(N\left(\mu, \sigma_{1}^{2}\right)\) 中抽出的样本, \(Y_{1}, \cdots, Y_{m}\) 是从正 态总体 \(N\left(\mu_{2}, \sigma_{2}^{2}\right)\) 中抽出的样本, 要求 \(\mu_{1}-\mu_{2}\) 的区间估计.
在本例中有
这里没有近似: 分布是严格成立的. 但是, 由于 \(\sigma_{1}, \sigma_{2}\) 末知, (4.15) 并不构成枢轴变量. 如果 \(n, m\) 都相当大,则 \(\sigma_{1}^{2}\) 和 \(\sigma_{2}^{2}\) 分别可用 \(X\) 样本的样本方差 \(S_{1}^{2}\) 和 \(Y\) 样本的样本方差 \(S_{2}^{2}\) 近似地代替之, 得
与(4.15)不同, (4.16) 只是近似而非严格. (4.16) 可作为枢轴变 量, 而得出 \(\mu_{1}-\mu_{2}\) 的区间估计. 当然, 其置信系数只是近似的.
例 4.5-4.8 所导出的区间估计, 叫 “大样本区间估计”. 一般 如果一个统计方法是基于有关变量的当样本大小 \(n\) 很大时的极 限分布, 则称这一统计方法为 “大样本方法”. 反之, 若依据的是有 关变量的确切分布,则称为 “小样本方法”. 如例 4.1-4.4 导出的 区间估计就是小样本区间估计.这不在于 \(n\) 多大多小: 在例 4.14.4 中, 即使样本大小 \(n=10^{10}\), 仍是小样本方法. 对例 4.5 而言, 因使用的是极限分布, 即使 \(n=40\), 仍算是大样本方法, 不言而喻, 大样本方法只有在样本大小较大时才宜于使用.
1.2. 4 置信界⚓︎
在实际问题中, 有时我们只对参数 \(\theta\) 的一端的界限感兴趣. 例如, \(\theta\) 是在一种物质中某种杂质的百分率,则我们可能只关心其 上界, 即要求找到这样一个统计量 \(\bar{\theta}\), 使 \(\{\theta \leqslant \bar{\theta}\}\) 的概率很大. \(\bar{\theta}\) 就称 为 \(\theta\) 的置信上界 (或上限). 又如, \(\theta\) 是某种材料的强度,则我们可 能只关心其下界, 即要求找到这样一个统计量 \(\theta\), 使 \(\{\theta \geqslant \theta\}\) 的概率
 文简单, 就以一个参数 \(\theta\) 的情况为例.
文简单, 就以一个参数 \(\theta\) 的情况为例.
定义 4.2 设 \(X_{1}, \cdots, X_{n}\) 是从某一总体中抽出的样本, 总体 分布包含末知参数 \(\theta, \bar{\theta}=\bar{\theta}\left(X_{1}, \cdots, X_{n}\right)\) 和 \(\underline{\theta}=\underline{\theta}\left(X_{1}, \cdots, X_{n}\right)\) 都是 统计量 (它们与 \(\theta\) 无关), 则
- 若对 \(\theta\) 的一切可取的值有
则称 \(\bar{\theta}\) 为 \(\theta\) 的一个置信系数为 \(1-\alpha\) 的置信上界; 2. 若对 \(\theta\) 的一切可取的值有
则称 \(\theta\) 为 \(\theta\) 的一个置信系数为 \(1-\alpha\) 的置信下界.
把(4.17)与(4.18) 与区间估计的置信系数定义去比较, 看出: 犆信上、下界无非是一种特殊的置信区间, 其一端为 \(\infty\) 或 \(-\infty\). 因 此, 前面用于求区间估计的方法, 都很容易平行地移至此处. 例如, 找 \(N\left(\mu, \sigma^{2}\right)\) 的均值 \(\mu\) 的置信下界, 假定 \(\sigma^{2}\) 已知, 以 \(\sqrt{n}(\bar{X}-\mu) / \sigma\) 为枢轴变量, 其分布为 \(N(0,1)\). 有
此式可改写为
把(4.19)与 (4.18) 比较, 即知 \(\bar{X}-u_{\alpha} \sigma / \sqrt{n}\) 为 \(\mu\) 的一个置信下界, 置信系数为 \(1-\alpha\). 将这个方法用于以前讨论过的诸例, 得出一些 䔜信上、下界的结果, 例如(记号均见有关各例):
- 例 \(4.1 \mu\) 的置信上、下界分别为(正号为上界)
- 例 \(4.2 \mu_{1}-\mu_{2}\) 的置信上、下界分别为 (正号为上界)
- 例 \(4.3 \sigma^{2}\) 的置信上界为 \((n-1) S^{2} / \chi_{n-1}^{2}(1-\alpha)\), 下界为 \((n-1) S^{2} / \chi_{n-1}^{2}(\alpha)\).
以上置信系数都是 \(1-\alpha\), 其余各例都与此类似,我们注意到 一点: 在置信区间中的 \(\alpha / 2\) 在这里都被 \(\alpha\) 取代. 这是由于区间估 计是双侧的. 共为 \(\alpha\) 的概率由两边均分, 各占 \(\alpha / 2\). 而置信界则是 单侧的.
1.3. 5 贝叶斯法⚓︎
用贝叶斯法处理统计问题的基本思想,已在 4.2 节 4.2.4 中 阐述过了. 用它来处理区间估计问题, 概念上和做法上都很简单: 沿用 4.2 节 4.2.4 中的记号. 在有了先验分布密度 \(h(\theta)\) 和样本 \(X_{1}, \cdots, X_{n}\) 后, 算出后验密度 \(h\left(\theta \mid X_{1}, \cdots, X_{n}\right)\). 再找两个数 \(\hat{\theta}_{1}, \hat{\theta}_{2}\) 都与 \(X_{1}, \cdots, X_{n}\) 有关,使
区间 \(\left[\hat{\theta}_{1}, \hat{\theta}_{2}\right]\) 的意思是: 在所得后验分布之下, \(\theta\) 落在这区间内的 概率为 \(1-\alpha\). 因此, \(\left[\hat{\theta}_{1}, \hat{\theta}_{2}\right]\) 可作为 \(\theta\) 的一区间估计, 其后验信度 为 \(1-\alpha\). “后验” 是指 “有了样本以后”的意思. 因此,所谓“后验信 度为 \(1-\alpha\) ”, 可以解释为: 在已有了样本以后, 我对区间 \(\left[\hat{\theta}_{1}, \hat{\theta}_{2}\right]\) 能包含末知参数 \(\theta\) 的相信程度为 \(1-\alpha\). 这与奈曼理论中 的置信系数的含义相似,但理论观念上有别. 因为这里整个架构根 本不同.
如果要找贝叶斯上下界,则只须把 (4.20)分别改为
和
对 (4.20) 而言还有一个问题: 满足条件 (4.20) 的 \(\hat{\theta}_{1}, \hat{\theta}_{2}\) 很多, 如何 决定一对? 一般是以使 \(\hat{\theta}_{1}-\hat{\theta}_{2}\) 最小为原则 \({ }^{*}\) (也可以是使 \(\hat{\theta}_{2} / \hat{\theta}_{1}\) 最小, 这要看参数的性质与实际问题中的要求如何而定). 下面将 通过例子解释这一点.
例 4.9 考虑例 2.14. 在该例中所规定的先验分布之下, 找 \(\theta\)
- 另一种可取的方法是找 \(\vec{\theta}_{1}, \hat{\theta}_{2}\), 使
的区间估计。
在该例中已找出 \(\theta\) 的后验分布为 \(N\left(t, \eta^{2}\right), t, \eta^{2}\) 分别由 (2.17), (2.18) 决定, 这个密度函数在 \(t\) 点处达到最大值, 然后在 两边对称地下降. 由此易见, 如要找 \(\hat{\theta}_{1}\) 和 \(\hat{\theta}_{2}\) 满足 (4.20) 式, 它只 有在 \(\hat{\theta}_{1}, \hat{\theta}_{2}=t \pm c\) 时才能使 \(\hat{\theta}_{2}-\hat{\theta}_{1}\) 最小. 由正态分布即知, \(c\) 必须 取为 \(\eta \mu_{\alpha}\). 于是得出贝叶斯区间估计
其后验信度为 \(1-\alpha\).
例 4.10 考虑例 2.13 . 在此已求出当取 \(R(0,1)\) 为先验分布 时, \(p\) 的后验密度为
要找 \(\hat{p}_{1}, \hat{p}_{2}\),使
并使 \(\hat{p}_{2}-\hat{p}_{1}\) 最小, 问题就麻烦些. (4.23) 的图形大致如图 4.3. 它在点 \(p=X / n\) 处 达到最大, 然后往两边下降. 故只有图中 \(c, d\) 那种对子, 才能使 \(d-c\) 最小. 方法 是: 先在 \(X / n\) 左边取定一个值 \(c\). 由方程
以 \(p\) 为末知量, 解出 \(p=d\). 从图 4.3 看
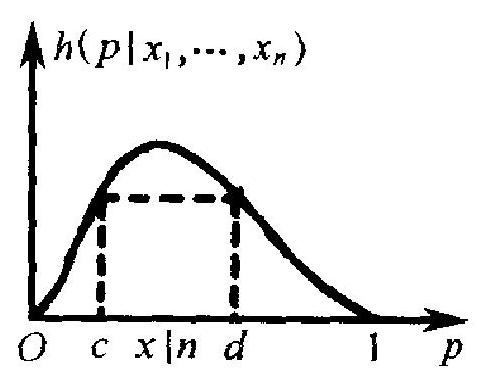 出, \(d\) 必大于 \(X / n\). 计算积分
出, \(d\) 必大于 \(X / n\). 计算积分
若 \(A>1-\alpha\), 表示 \(c\) 取得太小. 若 \(A<1-\alpha\), 则表示 \(c\) 取得太 大. 经过几次调整后即可找到足够接近的近似值.
与奈曼的理论相比,我们看出, 这里求区间估计的过程容易多 了. 固然, 在寻找适合 (4.20) 的 \(\hat{\theta}_{1}\) 和 \(\hat{\theta}_{2}\) 时, 往往计算很繁, 但并无 原则困难, 用计算机也很容易实现. 但用奈曼的方法, 则涉及到麻 烦的分布问题. 如例 4.1-4.4 这几个例, 就基于有关的统计量服 从 \(t\) 分布, 卡方和 \(F\) 分布等. 这不是常有的情况, 而只是少见的几 个特例(幸好这几个特例在实用中用得很多). 往往由于分布问题 无法解决, 而只好求助于大样本理论. 实用上往往样本不很大, 使 我们对由此而产生的误差(即实际的置信系数与名义的置信系数 的距离) 不甚了然. 贝叶斯方法不存在这些问题. 当然, 贝叶斯方法 有其自身的问题, 即先验分布如何定, 这一点我们在前面已提过 了
评论
登录github的账号后,可以直接在下方评论框中输入。
如果想进行更详细的讨论(如排版、上传图片等),选择一个反应后并点击上方的文字,进入论坛页面。