什么是参数估计?
1
设总体 服从 上的均匀分布, 密度函数为
其中 是未知参数, 试求 与 的极大似然估计值。
解:

详细解析:
为了求得 和 的极大似然估计值,我们首先需要得到似然函数。
设 是来自上述均匀分布的一个随机样本。那么,似然函数 为:
这个公式表示,在给定参数 和 的条件下,观察到整个样本序列 的概率(或密度)是每个单独观察值的概率密度的乘积。
求解极大似然估计值(MLE)是一种统计方法,用于通过最大化样本数据的似然函数来估计模型参数。对于这个问题,我们首先要理解的是,我们的样本数据来自一个区间 上的均匀分布,我们的目标是通过极大似然估计法找到 和 的估计值。
假设我们有一个样本,我们可以写出似然函数:
由于 在 的情况下,我们的似然函数变成了:
但是,这只在所有的 都处于 和 之间的情况下成立。这意味着 必须小于或等于样本中的最小值,而 必须大于或等于样本中的最大值。我们可以写作 和。
为了最大化似然函数,我们可以取对数以简化计算,并得到对数似然函数:
现在我们的目标是最大化。由于 必须是正数,我们可以看到,为了最大化,我们应该使 尽可能小。根据前面的讨论,这意味着 应该是样本中的最小值,而 应该是样本中的最大值。因此,我们得到极大似然估计值为:
2
设总体 的密度函数为
其中 的一组样本值为, 求参数 的矩估计值和极大似然估计值。
解:
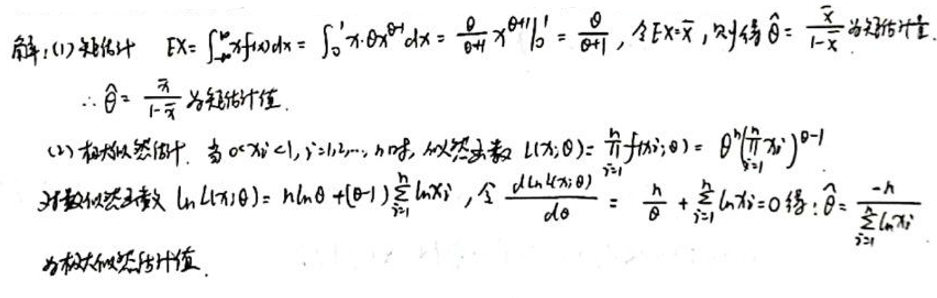
首先,我们求参数 的矩估计值。
矩估计法:
对于给定的密度函数,我们可以计算 的一阶原点矩为:
我们将计算这个期望值。
的一阶原点矩为:
现在,我们使用样本均值 来估计。因此,我们有:
从上式中解出,我们可以得到 的矩估计值。
接下来,我们求参数 的极大似然估计值。
极大似然估计法:
似然函数为:
取对数,我们得到对数似然函数:
为了找到 的极大似然估计值,我们需要对 求导并令其为0。我们将计算这个导数。
对数似然函数关于 的导数为:
为了找到 的极大似然估计值,我们需要令上述导数为0:
从上式中解出,我们可以得到 的极大似然估计值。
的极大似然估计值为:
总结: 1. 的矩估计值为: 2. 的极大似然估计值为:
这就是参数 的矩估计值和极大似然估计值。
3
设总体 的密度为 。求 的极大似然估计量, 并问所得估计量是否为 的无偏估计量?
解:
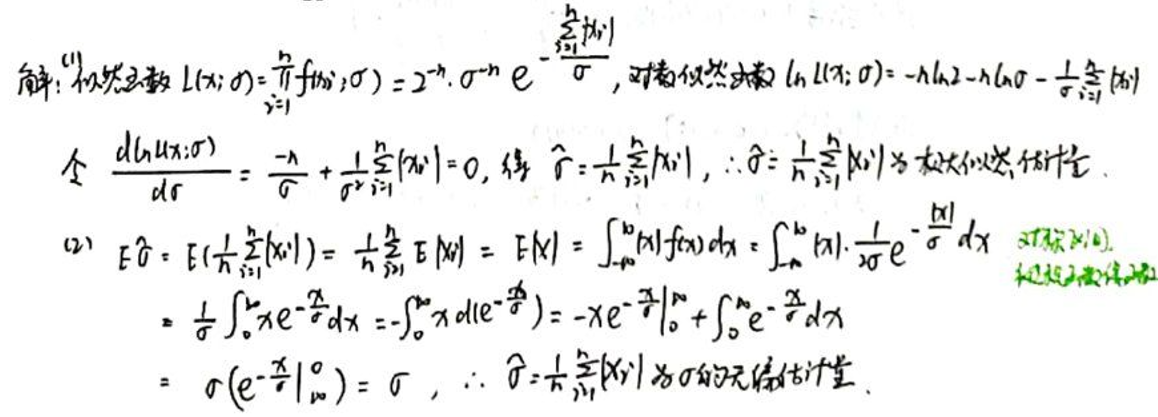 首先,我们求参数 的极大似然估计值。
首先,我们求参数 的极大似然估计值。
设 是来自上述分布的一个随机样本。那么,似然函数 为:
取对数,我们得到对数似然函数:
为了找到 的极大似然估计值,我们需要对 求导并令其为0。我们将计算这个导数。
对数似然函数关于 的导数为:
为了找到 的极大似然估计值,我们需要令上述导数为0:
从上式中解出,我们可以得到 的极大似然估计值。我们将解这个方程。
的极大似然估计值为:
接下来,我们要检查所得估计量 是否为 的无偏估计量。
为此,我们需要计算 的期望值 并检查它是否等于。
我们将计算这个期望值。
我们要求的是随机变量 的期望。给定的信息是:
以及 对于所有 。
为了求 的期望,我们可以使用期望的线性性质。期望的线性性质告诉我们,任何随机变量和常数的线性组合的期望等于这些随机变量和常数的期望的线性组合。
使用这个性质,我们有:
由于期望的线性性质,上式可以写为:
给定 ,我们可以进一步简化为:
所以, 的期望是 。
由于,我们可以得出结论:所得估计量 是 的无偏估计量。
4
验证二项分布 中 的无偏估计量 是优效估计。
证明:
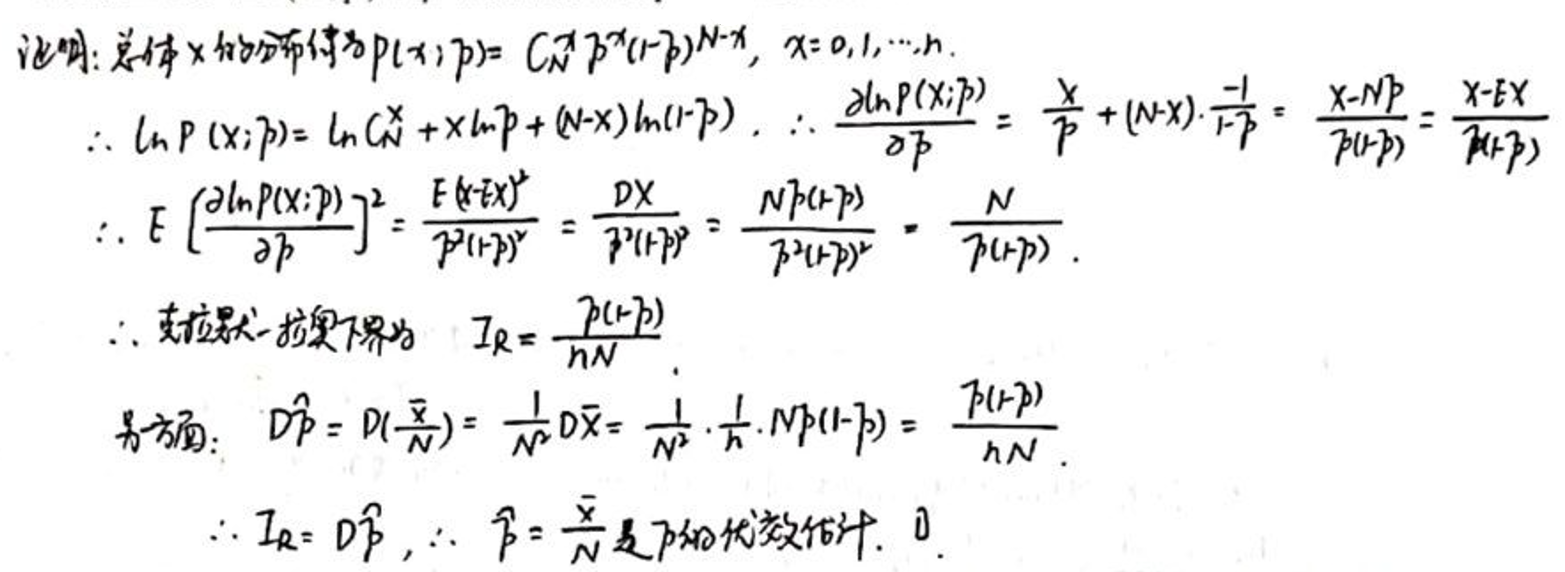
详细解析:
验证一个无偏估计量是否是优效估计,通常需要比较该估计量的方差与其他无偏估计量的方差。具体来说,如果一个无偏估计量的方差小于或等于其他所有无偏估计量的方差,那么该估计量就被认为是优效的。以下是验证步骤:
-
确定无偏性: 首先,确保估计量是无偏的。这意味着估计量的期望值等于参数的真实值。数学上,对于估计量 和参数 ,无偏性可以表示为:
-
计算估计量的方差: 计算给定无偏估计量的方差。
-
比较方差: 将给定无偏估计量的方差与其他无偏估计量的方差进行比较。如果给定估计量的方差小于或等于其他所有无偏估计量的方差,则该估计量是优效的。
-
考虑克拉默-拉奥下界: 对于某些模型,可以计算克拉默-拉奥下界(CRLB),这是任何无偏估计量方差的下限。如果估计量的方差等于CRLB,则该估计量不仅是无偏的,而且是有效的。
-
其他考虑因素: 在实际应用中,可能还需要考虑其他因素,如估计量的偏斜、峰度、稳定性等。
总之,验证一个无偏估计量是否是优效估计需要比较其方差与其他估计量的方差,并可能需要考虑克拉默-拉奥下界。如果一个估计量的方差达到了这个下界,并且小于或等于其他所有无偏估计量的方差,那么它就是优效的。
5
随机地从一批钉子中抽取 16 枚, 测得它们的平均长度为 2.125 厘米。设钉长分布为正态的, 若已知 厘米, 试求总体均值的置信度为 0.90 的置信区间。
解:

详细解析: 对于正态分布的总体,当 已知时,样本均值 的置信区间为: 其中:
- 是样本均值。
- 是总体标准差。
- 是样本大小。
- 是标准正态分布的上 分位数。
给定:
- 厘米
- 厘米
- 置信度为 0.90,所以。因此,。
我们需要查找 的值。然后,我们可以使用上述公式计算置信区间。
知道 对于标准正态分布大约是 1.645。
使用这个值,我们可以计算置信区间:
因此,总体均值的置信度为 0.90 的置信区间为 厘米。
6
从自动机床加工的同类零件中抽取 8 个, 测得样本均值 毫米, 样本标准差 毫米。如果零件长度服从正态分布, 求零件长度的数学期望 与标准差 的置信度为 0.95 的置信区间。
解:
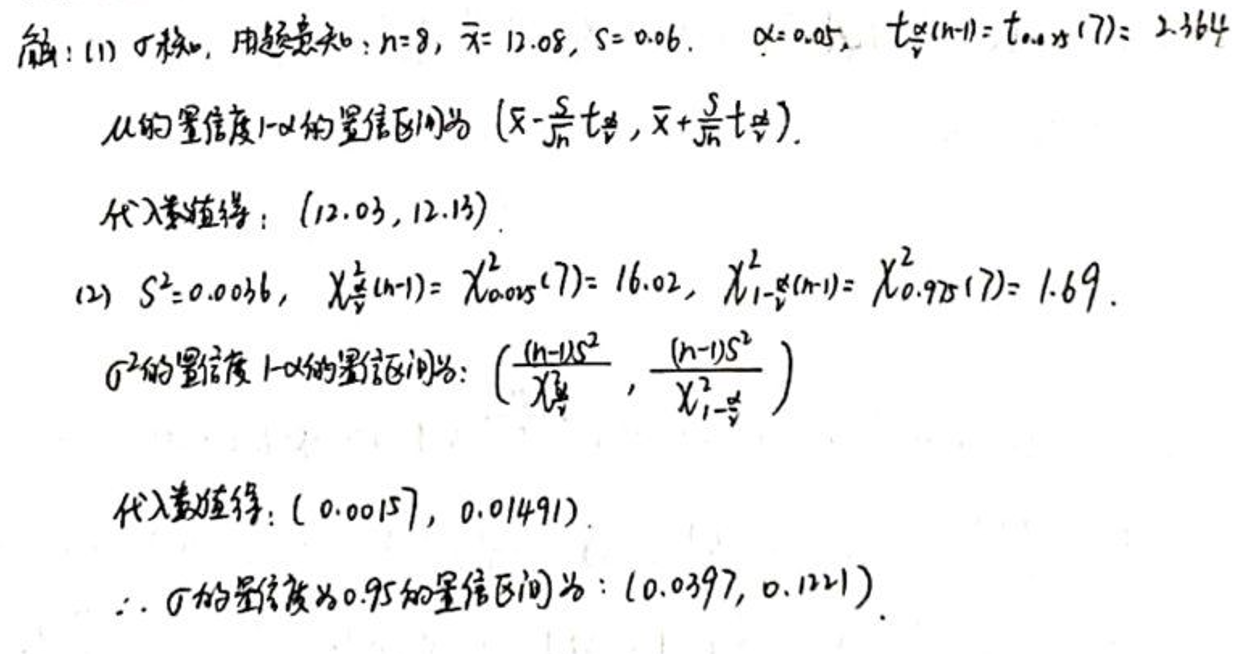 详细解析:
对于正态分布的总体,当 未知 时,我们使用 t 分布来计算置信区间。
详细解析:
对于正态分布的总体,当 未知 时,我们使用 t 分布来计算置信区间。
- 对于 的置信区间: 其中:
- 是样本均值。
- 是样本标准差。
- 是样本大小。
- 是自由度为 的 t 分布的上 分位数。
- 对于 的置信区间: 其中 和 是自由度为 的卡方分布的上 和下 分位数。
给定:
- 毫米
- 毫米
- 置信度为 0.95,所以。因此,。
我们首先需要查找, 和 的值。然后,我们可以使用上述公式计算置信区间。
对于自由度为 7 的 t 分布, 和 的值分别大约为 -2.3646 和 2.3646。
对于自由度为 7 的卡方分布, 和 的值分别大约为 16.013 和 1.69。
使用这些值,我们可以计算 和 的置信区间。
-
对于 的置信区间:
-
对于 的置信区间:
我们将计算这两个置信区间。
-
对于 的置信区间:
-
对于 的置信区间:
因此:
- 零件长度的数学期望 的置信度为 0.95 的置信区间为 毫米。
- 零件长度的标准差 的置信度为 0.95 的置信区间为 毫米。