介绍
置信区间(Confidence Interval)是统计学中的一个重要概念,用于估计一个参数的不确定性范围。这个参数可以是总体的均值、方差、比例等等。置信区间提供了一个区间范围,我们可以合理地认为真实的参数值位于这个区间内,以一定的置信水平,如95%或99%。
置信区间的基本思想是这样的:如果我们多次从同一个总体中随机抽取样本,并且每次都计算一个置信区间,那么这些置信区间中的一定比例(等于置信水平)将包含总体的真实参数值。
例如,假设我们有一个样本平均数为,样本标准差为,样本大小为,并且我们想要计算平均数的95%置信区间。在正态分布的假设下,95%置信区间可以用以下公式计算:
其中,是Z分数,对应于所选置信水平(在这里是95%)的正态分布的尾部面积。
需要注意的是,置信区间不是说有特定的概率包含总体参数。而是说,如果我们多次进行抽样和计算,那么这些置信区间中的一定比例将包含总体参数。
置信区间在各种领域都有广泛的应用,包括医学研究、经济学、工程学等,它们提供了一种量化估计参数不确定性的方法。
图
下面的图展示了正态分布曲线和与之相关的95%置信区间。在这个例子中,我们使用了Z分数和正态分布。
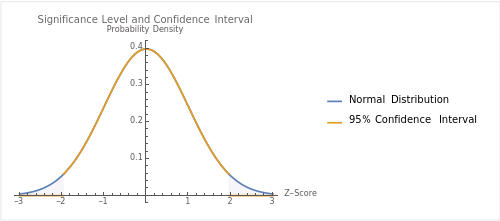
- 蓝色曲线表示正态分布的概率密度函数(PDF)。
- 灰色区域表示95%置信区间,即Z分数在-1.96和+1.96之间的区域。
在这个图中,你可以看到灰色区域(置信区间)占据了曲线下面积的大部分,这部分面积就是95%。而两侧的尾部(不在灰色区域内)各占据2.5%的面积,加起来就是5%,这就是显著性水平 。
这个图形直观地展示了如何通过显著性水平和置信区间来进行统计推断。希望这能帮助你更好地理解这两个概念。
概念
以下是置信区间的关键概念:
-
置信水平/置信度(Confidence Level):置信水平是一个介于0到1之间的概率,用1减去显著性水平的值来表示置信水平。例如,95%的置信水平对应的实际概率是0.95,或者以百分比表示为95%。这表示在不断重复的抽样中,有95%的可能性包含了真实的参数值。
-
置信区间的两个边界:置信区间通常由两个值组成,分别是下限和上限。这两个值构成了一个范围,用于估计参数值的不确定性。
-
构建置信区间的方法:构建置信区间的方法通常基于抽样和统计分析。最常见的方法之一是使用样本数据计算统计量(例如样本均值或样本标准差),然后利用概率分布理论,确定置信水平对应的临界值,进而计算出置信区间的下限和上限。
例如,假设我们要估计一个产品的平均寿命,我们可以进行一组寿命测试,然后使用统计方法计算出一个95%的置信区间。这个置信区间可以是 [50小时, 70小时],这意味着我们有95%的置信水平相信产品的平均寿命在50小时到70小时之间。
置信区间提供了一种量化参数估计的不确定性的方式,它告诉我们估计的精度和可靠性。通常,置信水平越高,置信区间就越宽,因为更高的可信度要求我们提供更大的不确定性范围,以确保参数值在区间内。
求解
求解置信区间(Confidence Interval, CI)的具体步骤取决于你所关心的参数(例如均值、比例或方差等)以及数据的分布(例如正态分布或其他分布)。以下是求解置信区间的一般步骤:
对于均值的置信区间(假设样本来自正态分布)
-
收集数据:收集一个大小为 的随机样本。
-
计算样本统计量:计算样本均值 和样本标准差 。
-
选择置信水平:置信水平通常表示为 ,其中 是显著性水平。例如,对于 95% 的置信水平,。
-
查找临界值:对于正态分布,临界值通常来自 -分布或 -分布。对于大样本(),通常使用 -分布。对于小样本,通常使用 -分布,自由度为 。
-
计算置信区间:
- 对于 -分布:
- 对于 -分布:
Z 还是t-分布
在统计推断中,通常根据样本大小以及所关心的参数的总体分布性质来选择使用 -分布还是 -分布。
使用 Z-分布的情况:
-
样本容量大(通常大于 30):当样本容量足够大时,中心极限定理适用,这意味着样本均值的分布接近于正态分布,无论总体分布如何。因此,对于大样本,通常可以使用 -分布。
-
已知总体标准差:如果你知道总体标准差(或者可以合理估计),那么可以使用 -分布。这通常用于总体分布是正态分布的情况。
使用 t-分布的情况:
-
样本容量小:当样本容量相对较小(通常小于 30)时,样本均值的分布不一定近似于正态分布,因此需要使用 -分布。-分布更宽泛,更适合于小样本情况。
-
总体标准差未知:如果总体标准差未知,而你使用样本标准差来估计它,那么应该使用 -分布。这是因为在这种情况下,估计的标准差引入了额外的不确定性。
-
总体分布未知或不是正态分布:当你不知道总体分布或知道总体分布不是正态分布时,也可以使用 -分布,因为它对总体分布的形状不做特定假设。
总之,根据样本容量、总体标准差是否已知以及总体分布的知识来选择使用 -分布或 -分布。如果不确定,通常使用 -分布是一个较为保守的选择,因为它对样本大小较小和总体标准差未知的情况更具鲁棒性。
对于标准差的置信区间
要计算标准差的置信区间,通常使用卡方分布(Chi-Square distribution)。下面是计算标准差置信区间的一般步骤:
-
收集数据:收集一个大小为 的样本。
-
计算样本标准差:计算样本标准差 。
-
选择置信水平:确定你感兴趣的置信水平(通常表示为 )。
-
计算置信区间:
- 下限:
- 上限:
这里, 和 分别是自由度为 的卡方分布的分位数,使得积分从左侧或右侧分别累积到置信水平 和 处。
这样就得到了标准差的置信区间,它告诉你标准差的估计值有多大的不确定性,以置信水平 来表示。
请注意,标准差的置信区间通常在实际应用中不太常见,因为更常见的是计算均值的置信区间。标准差的置信区间通常用于特定问题或研究中,例如质量控制或实验设计等。
对于比例的置信区间
-
收集数据:从总体中随机抽取 个样本。
-
计算样本比例:
-
选择置信水平和查找临界值:与上面相同。
-
计算置信区间:
这些只是一些基础的例子。置信区间的计算可以更复杂,特别是当你处理更复杂的统计模型或非正态分布时。
如果你有具体的数据或问题,我可以帮助你计算置信区间。
置信水平和显著性水平的关系
置信水平和显著性水平是统计学中两个重要的概念,它们在某种程度上是互补的,但它们用于不同的统计方法。下面是它们的定义和关系:
-
置信水平(Confidence Level):
- 用于描述置信区间的宽度和可靠性。
- 表示我们有多大的信心,该区间包含了总体的真实参数值。
- 常见的置信水平有90%,95%,99%等。
- 例如,95%的置信水平意味着,如果我们多次从同一个总体中随机抽取样本并计算置信区间,那么大约95%的置信区间会包含总体的真实参数值。
-
显著性水平(Significance Level,通常表示为 ):
- 用于假设检验,描述拒绝原假设的风险水平。
- 是你愿意接受的第一类错误(Type I error)的概率,即错误地拒绝原假设的概率。
- 常见的显著性水平有0.05(或5%),0.01(或1%)等。
- 例如, 意味着你愿意接受5%的风险,错误地拒绝原假设。
它们之间的关系:
置信水平和显著性水平加起来总是等于1。换句话说:
例如,如果显著性水平 是0.05(或5%),那么对应的置信水平是95%。
这种关系可以这样理解:如果我们进行假设检验并设定显著性水平为5%,那么我们有5%的风险错误地拒绝原假设。与此相反,如果我们计算一个95%的置信区间,那么我们有95%的信心,该区间包含了总体的真实参数值。
尽管这两个概念在某种程度上是互补的,但它们用于不同的统计方法和目的,因此在实际应用中应该明确区分。
置信区间中的显著性水平
在置信区间的上下文中,(通常称为“alpha水平”或“显著性水平”)是用于表示1减去置信水平的值。换句话说,如果置信水平是95%,那么就是5%或0.05。
用于确定置信区间的端点。在正态分布的情况下,通常分为两个尾部,每个尾部占据的面积。例如,对于95%的置信水平(即),两个尾部各占据0.025的面积。
值与Z分数或t分数有关,这取决于样本大小和分布。这些分数用于计算置信区间的上下限。
- 在Z分数的情况下,对于95%的置信水平(),Z分数通常是1.96(两侧各占据0.025的面积)。
- 在t分数的情况下,该值取决于样本大小和自由度,通常通过查阅t分布表或使用统计软件来确定。
总体来说,是一种用于量化置信区间不确定性和风险水平的方式。它帮助我们理解,在多次抽样和计算置信区间的过程中,有多少比例的置信区间不会包含总体参数。