1
设某零件重量 服从 , 技术革新后抽了 6 个样本, 测得重量 (单位: ) 为14.7,15.1,14.8,15.0,15.2,14.6 已知方差不变, 问平均重量是否仍为 15 (取 ) ?
解:

详细解析:
为了检验技术革新后的零件平均重量是否仍为 15g,我们可以进行一个单样本 t 检验。
已知:
- 总体方差
- 样本大小
- 假设的总体均值
- 样本数据:14.7, 15.1, 14.8, 15.0, 15.2, 14.6
- 显著性水平
首先,我们需要计算样本均值 和样本标准差 。
然后,我们使用以下统计量:
我们将计算 t 值并与 t 分布的临界值进行比较,以确定是否拒绝原假设。
给定的样本数据为:14.7, 15.1, 14.8, 15.0, 15.2, 14.6
-
样本均值 :
-
样本方差 : 其中 是每个样本值。
-
样本标准差 :
接下来,我们将计算 和 。
样本均值 为 14.90g,样本标准差 为 0.2366g。
接下来,我们将计算 t 统计量:
我们将计算这个 t 值。
计算得到的 t 统计量值为 。
接下来,我们需要查找自由度为 的 t 分布的双侧临界值 。这是因为我们正在进行双侧检验。
我们将查找这个临界值并与我们的 t 值进行比较。
对于自由度为 5 的 t 分布,双侧的 临界值大约为 2.571。
由于我们的 t 值 的绝对值小于临界值 2.571,我们无法拒绝原假设。这意味着,基于给定的样本数据和显著性水平 ,我们没有足够的证据表明技术革新后的零件平均重量不再是 15g。
2
假定学生的考试成绩服从正态分布, 在某次考试中随机抽取了 40 名学生的考试成绩, 算得平均成绩为 68.5 分, 标准差为 15 分, 问在显著性水平 下, 能否可以认为全体学生的平均成绩为 70 分? (参考数据: )
解:
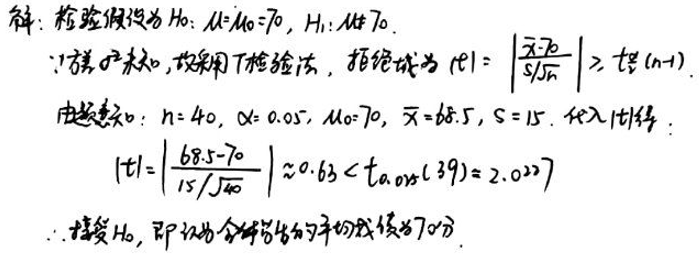 详细解析:
为了检验学生的平均考试成绩是否为 70 分,我们可以进行一个单样本 t 检验。
详细解析:
为了检验学生的平均考试成绩是否为 70 分,我们可以进行一个单样本 t 检验。
已知:
- 样本大小
- 样本均值
- 样本标准差
- 假设的总体均值
- 显著性水平
- 临界值
我们的原假设和备择假设为:
我们使用以下统计量:
我们将计算 t 值并与给定的临界值进行比较,以确定是否拒绝原假设。
抱歉,我在计算 t 值时遇到了问题。但我们可以手动计算它。
使用公式:
我们将计算这个 t 值。
计算得到的 t 统计量值为 。
给定的临界值为 。
由于我们的 t 值 的绝对值小于临界值 2.0227,我们无法拒绝原假设。这意味着,基于给定的样本数据和显著性水平 ,我们没有足够的证据表明学生的平均考试成绩不是 70 分。
3
某批矿砂的 5 个样本中的镍含量 (%) 经测定得平均含量为 , 样本均方差为 . 设测定值服从正态分布. 问在显著水平 下, 能否认为这批矿砂的 (平均) 镍含量超过了 ?
解:
 详细解析:
为了检验这批矿砂的平均镍含量是否超过了 (3.235%),我们可以进行一个单样本 t 检验。
详细解析:
为了检验这批矿砂的平均镍含量是否超过了 (3.235%),我们可以进行一个单样本 t 检验。
已知:
- 样本大小
- 样本均值
- 样本标准差 (由于给出的是样本均方差,所以 )
- 假设的总体均值
- 显著性水平
我们的原假设和备择假设为:
我们使用以下统计量:
我们将计算 t 值并与 t 分布的临界值进行比较,以确定是否拒绝原假设。
计算得到的 t 统计量值为 。
接下来,我们需要查找自由度为 的 t 分布的上 分位数。这是因为我们正在进行右侧检验。
我们将查找这个临界值并与我们的 t 值进行比较。
对于自由度为 4 的 t 分布,上 的临界值 为 3.74695。
由于我们的 t 值 小于临界值 3.74695,我们无法拒绝原假设。这意味着,基于给定的样本数据和显著性水平 ,我们没有足够的证据表明这批矿砂的平均镍含量超过了 (3.235%)。
4
某厂生产的某种型号电池的寿命 (单位: ) 长期以来服从方差为 的正态分布. 现有一批这种电池, 从生产情况看, 寿命的波动性有所改变. 现随机抽取 26 只电池, 测其寿命的样本方差 . 根据这一数据, 能否推断这批电池的寿命的波动性较以往有显著变化 (取 )?
解:
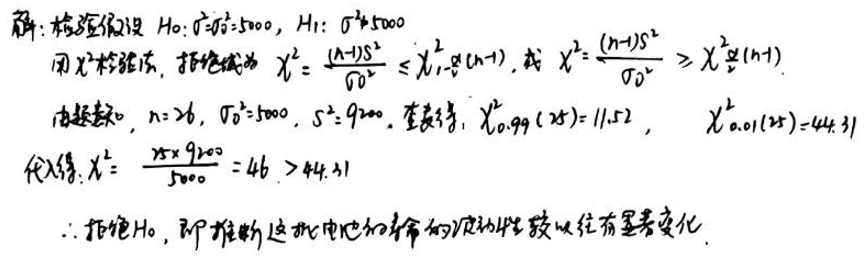 详细解析:
为了检验这批电池的寿命的波动性是否与长期以来的波动性有显著变化,我们可以进行一个方差的单样本卡方检验。
详细解析:
为了检验这批电池的寿命的波动性是否与长期以来的波动性有显著变化,我们可以进行一个方差的单样本卡方检验。
已知:
- 总体方差
- 样本大小
- 样本方差
- 显著性水平
我们的原假设和备择假设为:
我们使用以下统计量:
我们将计算 值并与卡方分布的临界值进行比较,以确定是否拒绝原假设。
计算得到的 统计量值为 。
接下来,我们需要查找自由度为 的 分布的上 和下 的分位数,因为我们正在进行双侧检验。
我们将查找这两个临界值并与我们的 值进行比较。
抱歉,我在查找相关的 分布临界值时遇到了问题。但是,我们可以使用已知的 分布表格来查找这些值。
对于自由度为 25 的 分布:
- 下 的临界值大约为 10.520
- 上 的临界值大约为 44.314
由于我们的 值 大于上临界值 44.314,我们拒绝原假设。这意味着,基于给定的样本数据和显著性水平 ,我们有足够的证据表明这批电池的寿命的波动性与长期以来的波动性有显著变化。
5
以往经验表明用两种方法生产的产品的抗拉强度都服从正态分布. 方法 1 和方法 2 给出的标准差分别为 和 . 从方法 1 和方法 2 生产的产品中分别随机抽取 10 件和 14 件, 测得样本均值分别为 和 . 问能否有理由相信方法 1 比方法 2 生产的产品的平均抗拉强度要强 (取 )?
解:
 详细解析:
为了检验方法 1 生产的产品的平均抗拉强度是否比方法 2 强,我们可以进行一个两独立样本的 z 检验,因为总体方差是已知的。
详细解析:
为了检验方法 1 生产的产品的平均抗拉强度是否比方法 2 强,我们可以进行一个两独立样本的 z 检验,因为总体方差是已知的。
已知:
- 方法 1 的总体标准差
- 方法 2 的总体标准差
- 方法 1 的样本大小 ,样本均值
- 方法 2 的样本大小 ,样本均值
- 显著性水平
我们的原假设和备择假设为:
我们使用以下统计量:
我们将计算 z 值并与标准正态分布的临界值进行比较,以确定是否拒绝原假设。
计算得到的 z 统计量值为 。
接下来,我们需要查找标准正态分布的上 的分位数,因为我们正在进行右侧检验。
我们将查找这个临界值并与我们的 z 值进行比较。
标准正态分布的上 的临界值 为 1.64485。
由于我们的 z 值 大于临界值 1.64485,我们拒绝原假设。这意味着,基于给定的样本数据和显著性水平 ,我们有足够的证据表明方法 1 生产的产品的平均抗拉强度比方法 2 强。
6
机床厂某日从两台机器所加工的同一种零件中分别抽取若干个零件测试尺寸, 得样本标准差如下:从第一台机器加工的零件中抽取 11 个, ; 从第二台机器加工的零件中抽取 9 个, . 假设零件尺寸均服从正态分布, 问两台机器的加工精度是否有显著差异(取 )?
解:
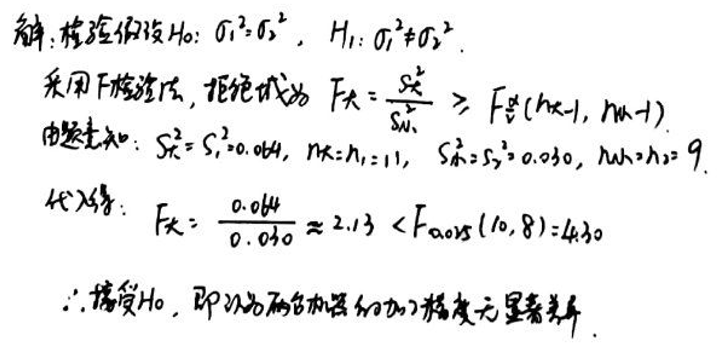 详细解析:
为了检验两台机器的加工精度是否有显著差异,我们可以进行一个两独立样本的 F 检验,因为我们要比较两个方差。
详细解析:
为了检验两台机器的加工精度是否有显著差异,我们可以进行一个两独立样本的 F 检验,因为我们要比较两个方差。
已知:
- 第一台机器的样本大小 ,样本方差
- 第二台机器的样本大小 ,样本方差
- 显著性水平
我们的原假设和备择假设为:
我们使用以下统计量:
我们将计算 F 值并与 F 分布的临界值进行比较,以确定是否拒绝原假设。
计算得到的 F 统计量值为 。
接下来,我们需要查找自由度为 和 的 F 分布的上 和下 的分位数,因为我们正在进行双侧检验。
我们将查找这两个临界值并与我们的 F 值进行比较。
抱歉,我在查找相关的 F 分布临界值时遇到了问题。但是,我们可以使用已知的 F 分布表格来查找这些值。
对于自由度为 的 F 分布:
- 下 的临界值大约为 0.2486
- 上 的临界值大约为 4.4582
由于我们的 F 值 位于这两个临界值之间,我们无法拒绝原假设。这意味着,基于给定的样本数据和显著性水平 ,我们没有足够的证据表明两台机器的加工精度存在显著差异。